
 提问题
提问题
 写回答
写回答
 写文章
写文章
 发视频
发视频
186
顶
在JavaScript中,确保某些脚本或模块优先加载通常涉及几个策略。这些策略可以帮助确保关键功能或资源在页面加载时尽快可用。以下是几种常见的策略:1. 使用<script>标签的defer或async属性defer属性defer属性告诉浏览器立即下载脚本,但延迟执行脚本直到HTML文档完全解析和显示。这对于依赖DOM的脚本非常有用。<script src="script.js" defer></script>async属性async属性同样告诉浏览器立即下载脚本,但与defer不同的是,脚本一旦下载完成就会立即执行,不保证按照它们在页面中出现的顺序执行。<script src="script.js" async></script>2. 使用动态脚本加载你可以在文档加载完成后使用JavaScript动态创建并加载脚本。这种方法允许更细粒度的控制加载顺序。document.addEventListener('DOMContentLoaded', (event) => { const script = document.createElement('script');
script.src = 'path/to/your/script.js'; document.head.appendChild(script);
});3. 使用<script>标签的type="module"如果你使用的是ES6模块,可以使用type="module"属性,这有助于浏览器按照模块依赖关系来加载和执行脚本。<script type="module" src="module.js"></script>4. 显式设置优先级(使用<link rel="preload">)对于非脚本资源(如CSS文件或字体),可以使用<link rel="preload">来指示浏览器立即加载这些资源。虽然这不直接应用于JavaScript,但它可以用于确保关键资源尽早加载。<link rel="preload" href="style.css" as="style">5. 使用<script>标签的defer属性并结合DOMContentLoaded事件如果你需要某些脚本在DOM完全加载后立即执行,但又不希望它们阻塞HTML解析,可以使用defer并配合事件监听。<script src="priority-script.js" defer></script><script>
document.addEventListener('DOMContentLoaded', function() { // 你的代码可以在这里执行,确保DOM已完全加载。
});</script>结论选择哪种策略取决于你的具体需求:是希望脚本尽快执行以优化用户体验,还是希望脚本的执行不阻塞页面的渲染。通常,合理利用defer和async属性,以及动态脚本加载,可以有效地管理脚本的加载顺序和执行时机。对于非脚本资源,使用<link rel="preload">可以帮助提升整体加载性能。

184
在上网时,偶尔看到好玩的动图,想从网上下载动图使用,比如做表情包动图,或者上传到文章中增加内容的趣味性等。但是有时会出现,GIF图片下载到电脑后,或者保存到手机后变成静态图片的情况,动图下载后变成静态图片了。出现这样的问题,是因为下载的图片格式改变了,所以图片就变成静态而不是动态了。本来动态图片的格式是GIF格式,但是下载下来道图片就会扩展名为JPG格式。电脑端在下载时,修改图片的格式为gif,这样就可以了。手机端如果方案1无效,那就先把图片下载到电脑,手机和电脑各登陆一个QQ,用电脑发送动态图片到手机上,手机接收后直接保存即可。把图片下载的时候保存格式修改为GIF格式,打开手机相册查看时,下载一个gif图片查看器即可。通过以上技巧,快速的解决GIF图片保存的问题,简单,快捷。
182
PHP通过session实现单IP登录限制,主要目的是为了提高系统的安全性、防止帐户被多人同时使用。实现这一功能的关键技术点包括:1. 会话管理、2. IP地址的识别与记录、3. 登录状态的检测与限制。我们将重点讨论会话管理在实现单IP登录限制中的应用。会话管理涉及到用户登录状态的跟踪,保证系统可以识别出每个独立的用户。通过PHP的session机制,我们可以在用户登录时记录其IP地址,并在后续访问中检查当前请求的IP地址是否与记录的IP地址一致。如果不一致,则可判定为非法访问或多地点登录尝试,据此限制登录或强制下线。会话管理的正确实施是确保单IP登录限制有效性的基础。一、会话与IP地址管理会话初始化在用户首次登录时,系统应初始化一个会话,记录用户的登录信息,包括用户ID和登录时的IP地址。这一步是通过PHP的 session_start() 函数实现的。会话信息存储在服务器上,每个会话配有一个唯一的会话ID,通过客户端的cookie进行交互。记录用户IP在会话初始化后,系统需获取并记录用户的实际IP地址。PHP可以通过$_SERVER['REMOTE_ADDR']获取当前请求的IP地址。然后,将此IP地址存储至会话变量中,例如$_SESSION['user_ip'] = $_SERVER['REMOTE_ADDR']。二、登录状态的检测与限制登录状态验证在用户每次请求时,除了检查会话ID是否存在、会话是否有效外,还需要验证请求的IP地址是否与会话记录中的IP地址一致。如果IP地址发生变化,可以认为是不同地点的登录尝试,根据实际需求强制该用户下线或进行其他安全处理。实施登录限制在检测到IP地址变化或非法登录尝试时,应立即终止当前会话(session_destroy()),清除与用户会话相关的所有数据,同时可能需要记录此次事件作为安全审计的一部分。三、安全性增强使用HTTPS为防止会话ID被截获使用,确保会话的安全性,建议使用HTTPS协议加密数据传输,避免会话信息在传输过程中被窃取。结合其他安全措施单IP登录限制是众多安全措施中的一项,为了更全面地保护系统安全,它应当与密码强度要求、验证码校验、登录尝试次数限制等安全措施结合使用。四、实际案例分析通过分析一个在线交易平台的实际案例,其中通过使用PHP会话管理和IP检测机制实现了单IP登录限制。通过设置合理的登录检测逻辑,既保证了用户体验,又显著提高了账户安全性。综上,PHP利用session实现单IP登录限制是一个涵盖会话管理、IP地址检测与安全措施等多个方面的过程。它能有效防止账户的多地登录使用,增强系统安全。然而,这只是安全措施中的一环,应结合其他技术综合保护用户账户安全。相关问答FAQs:1. 如何使用PHP session来实现单IP登录限制?处理单IP登录限制可以通过PHP session来实现。下面是一种基本的方法:首先,当用户登录时,将用户的IP地址保存在session变量中,例如$_SESSION['user_ip'] = $_SERVER['REMOTE_ADDR'];。其次,检查用户的IP地址是否与之前保存在session中的IP地址匹配。可以使用条件语句来判断,例如if($_SESSION['user_ip'] != $_SERVER['REMOTE_ADDR']) { // 强制退出登录 }。另外,还可以在登录页面添加验证机制,如果发现当前IP地址已经在其他地方登录,则要求用户确认是否继续登录,或者自动退出之前的登录状态。此外,可以考虑设置登录尝试次数限制,例如限制用户每分钟内只能尝试登录几次,从而防止暴力破解。2. PHP session如何防止用户通过代理IP绕过单IP登录限制?为了防止用户通过代理IP绕过单IP登录限制,可以采取以下措施:使用服务器端语言(如PHP)检测HTTP头中的X-Forwarded-For字段,该字段可用于获取真实的客户端IP地址,尽管客户端使用了代理。验证X-Forwarded-For字段中的IP地址,以确保其不属于已知的代理IP地址列表。您可以维护一个代理IP地址的黑名单,在登录过程中检查用户的IP地址是否出现在黑名单中,如果是,可以拒绝该登录请求。可以考虑使用第三方服务提供商提供的IP代理检测工具或API,这些工具可以帮助您确定用户是否正在使用代理服务器。3. 如何通过PHP session实现单IP登录限制的更高级方法?除了基本的单IP登录限制之外,还有一些更高级的方法可以进一步提升安全性:可以考虑使用令牌或密钥来验证每个会话。在用户登录成功后,生成一个唯一的令牌或密钥,并将其存储在session中和用户的数据库记录中。每次请求时,验证session中的令牌或密钥与数据库中的一致性。可以在单IP登录限制之外添加其他因素,如用户浏览器指纹识别、设备识别、验证码等。可以考虑使用JWT(JSON Web Token)作为应用程序的身份验证机制,JWT包含了用户的基本信息,并且可以设置过期时间,从而增加了安全性。如果需要更高级的安全控制,建议使用专业的身份验证和授权框架,如Laravel提供的Passport模块或Symfony的安全组件等。这些框架提供了更多功能和选项来管理用户会话和访问权限。

173
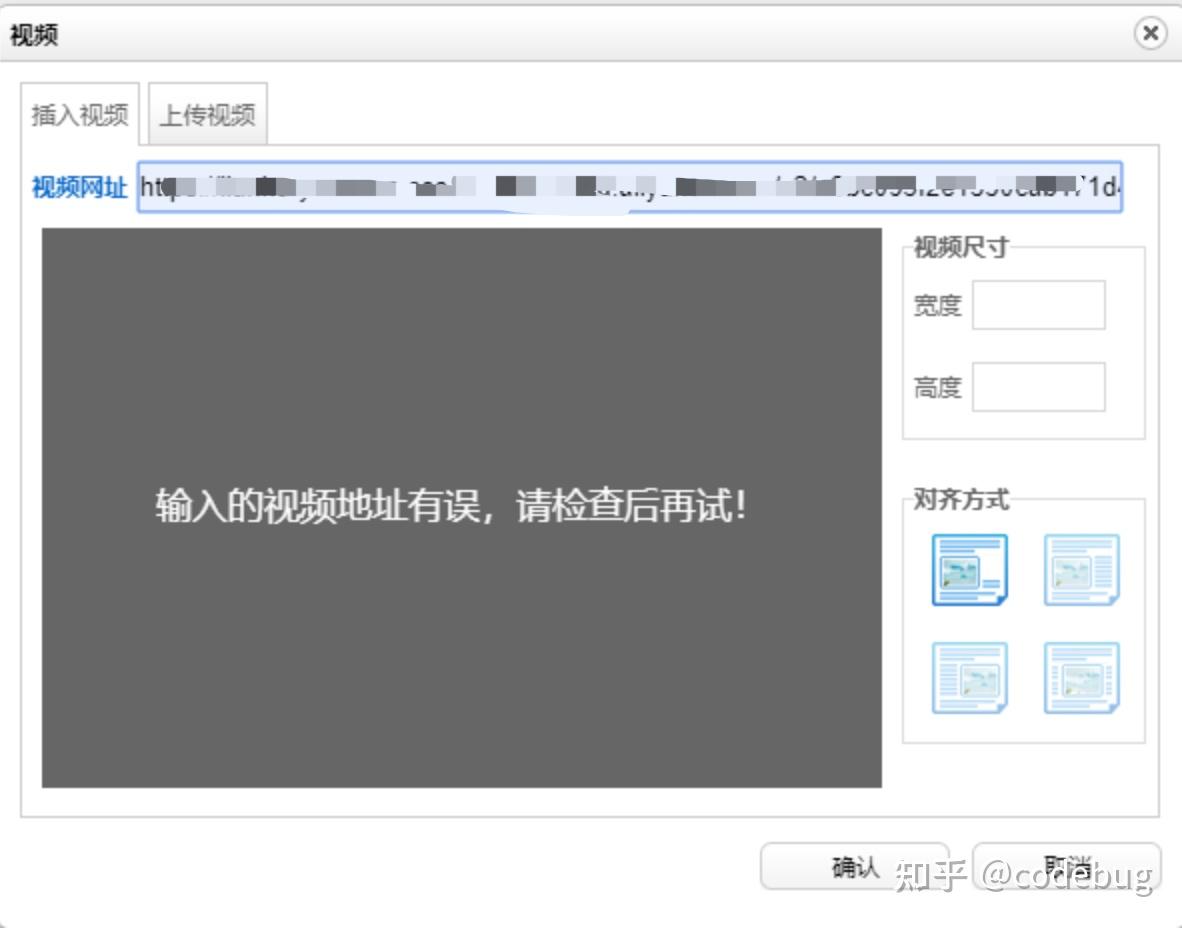
问题一:提示 “输入的视频地址有误,请检查后再试! “解决方法1、打开文件: ueditor.all.js;搜索 me.commands["insertvideo"]把html html.push(creatInsertStr( vi.url, vi.width || 420, vi.height || 280, id + i, null, cl, 'image'));改为插入的 embed 标签html.push(creatInsertStr( vi.url, vi.width || 420, vi.height || 280, id + i, null, cl, 'embed'));2、打开文件:ueditor.config.js;搜索:whitList;img里面添加"_url"然后在最后增加:source: ['src', 'type'],
embed: ['type', 'class', 'pluginspage', 'src', 'width', 'height', 'align', 'style', 'wmode', 'play','autoplay','loop', 'menu', 'allowscriptaccess', 'allowfullscreen', 'controls', 'preload'],
iframe: ['src', 'class', 'height', 'width', 'max-width', 'max-height', 'align', 'frameborder', 'allowfullscreen']3、打开文件: dialogs/video/video.js;搜索 function createPreviewVideo(url)把下面的内容替换$G("preview").innerHTML = '<video class="previewVideo" controls="controls" src="'+conUrl+'" style="width:420;height:280 "></video>';问题二:ueditor 在上传视频之后,编辑页面,显示空白。查看html有视频,就是显示空白打开文件: ueditor.all.js,搜索 setContent: function (html, isAppendTo, notFireSelectionchange)问题三:上传之后,无法关闭弹窗是因为改动embed后,下面红框的代码无法正常找到image标签及其里面的属性导致的打开文件:ueditor.all.js;搜索me.commands["insertvideo"], 注释掉红框部分;问题四:视频无法显示问题打开文件:ueditor.all.js;搜索case 'embed'把str = '<embed type="application/x-shockwave-flash" class="' + classname + '" pluginspage="http://www.macromedia.com/go/getflashplayer"' +
' src="' + utils.html(url) + '" width="' + width + '" height="' + height + '"' + (align ? ' style="float:' + align + '"': '') +
' wmode="transparent" play="true" loop="false" menu="false" allowscriptaccess="never" allowfullscreen="true" >';
break;改为str = '<embed src="' + utils.html(url) + '" width="' + width + '" height="' + height + '"' + (align ? ' style="float:' + align + '"': '') +
' wmode="transparent" play="true" loop="false" menu="false" allowscriptaccess="never" allowfullscreen="true" >';
break;其实,就是去掉了:type="application/x-shockwave-flash" class="' + classname + '" pluginspage="http://www.macromedia.com/go/getflashplayer"' +'问题五:如何设置一个封面(针对的是video标签)这种方式就是给所有的视频都添加一个默认封面图,图片就是ueditor.all.js中的添加的那个。修改ueditor.config.js中的xss过滤白名单,修改内容如下:添加poster属性然后修改ueditor.all.js中的内容,修改内容如下另一种方式是使用视频中的内容作为封面,没办法选帧数。在ueditor.all.js中添加 preload=“meta”属性值位置如下图所示。以上两种方式都可以解决没有上传视频封面的问题问题六:embed标签如何设置视频自动播放,这个去查看embed标签的属性就知道了,修改属性值play="true"就可以自动播放了
172
熟悉的QQ回来了”,昨天(12月8日),腾讯QQ正式宣布:经典模式回归!这让不少网友直呼“熟悉的感觉终于回来了”。经典模式QQ的回归,重新引入了广受老用户喜爱的窄面板与独立聊天窗口设计,PC端QQ支持双模式切换,用户可自定义消息列表和聊天窗口的分合。此外,还支持批量导入表情包、导入历史版本聊天记录等。许多老用户熟悉的个性签名、天气、资料卡等经典功能也将在近期版本陆续回归。对很多人来说,QQ不只是工具,更是承载着青春的时光注解,可能如今虽然不常上线,但那里安放着的,或是无可替代的回忆。

171
WinWebMail是一款功能强大的邮件服务器,有的用户使用WinWebMail建立邮件服务器后,却发现不能对外发邮件,也就是说向外部(英特网)邮箱发信总是失败,这是怎么回事,下边就为大家介绍一下。一、DNS的原因:在大部分情况下对外部(英特网)邮箱发信失败都是因为DNS设置不当或所使用的DNS服务器无法正常工作引起的。您可以在服务器上点击右下角图标,然后在弹出菜单中选取“服务”项后查看所设置的DNS服务器地址(见下图)。您需确认:1. 是否设置有DNS服务器地址。2. 所设置的DNS服务器地址是否是有效的。3. 此DNS服务器是否正常工作。您可以试试下面这些DNS地址,或直接询问本地ISP服务提供商:205.252.144.228202.106.127.1216.239.32.10168.95.1.1202.102.192.68202.106.0.20202.96.199.133202.106.196.115202.96.96.235202.103.226.68202.96.96.236202.103.224.68210.162.122.114解决办法:1. 在这种情况下更改DNS地址是个好主意(更改DNS成功后必须要重新启动一下WinWebMail服务才能生效)。2. 输入另一个不同的备用DNS地址,这样当首选DNS暂停服务时,WinWebMail将可以自动使用备用DNS服务器进行目标地址的解析和投递,从而保证通讯畅通。3. 绝大部分情况下,请不要将局域网内的某台机器IP(如:10.96.0.1)做为DNS服务器地址。4. 为了确认所选用的DNS可以正常使用,您可以在服务器上ping该DNS地址,当可以ping通时,即可以认为该DNS能够正常工作。请优先选择响应时间最短的DNS,因为这样将可以大幅提高外发邮件的速度。二、系统安全设置或防火墙的设置造成无法对外进行UDP通讯的原因:因为邮件系统对外发信时需要和DNS服务器就目标邮件服务器的地址解析进行UDP通讯,所以您必须允许UDP包通过,如果出于安全原因要封UDP端口时,您也必须开放1024以上的UDP端口。三、在服务器端启用了防病毒软件中的邮件扫描功能:解决办法:禁用服务器端防病毒软件中的邮件扫描功能。四、垃圾邮件过多,从而堵塞服务器的发信进程也会造成外发邮件的失败:解决办法,请参照这里的详细说明:http://www.veryhuo.com/a/view/153761.html五、防病毒软件设置不当:您需要正确设置所安装的防病毒软件后才可以和邮件系统正常协同工作。服务器端我们建议安装McAfee VirusScan或Norton。只要在服务器端安装有防病毒软件时,就必须在防病毒软件的查毒设置中排除掉邮件系统安装目录下的 \mail 及其所有子目录和 \msgca 及其所有子目录,否则有可能出现邮件计数错误,从而造成邮箱满的假象。六、如果您的邮件域名没有被解析到安装WinWebMail服务器的IP地址时,也会造成对部分邮件服务器投递失败。七、如果您的服务器IP地址被反垃圾邮件组织列入黑名单后,也会造成无法对外(特别是对国外)发送电子邮件:解决办法:您可以在http://www.kloth.net/services/dnsbl.phphttp://www.dnsbl.info/处提交您的邮件服务器IP地址,查询结果中底色为红色的就是将您的IP加入黑名单的网站,您可以到该网站申请移除就可以解决了。八、国外的不少邮件服务器为防止垃圾邮件,会过滤包含中文字符集的电子邮件,或直接拒收所有来自国内IP段的电子邮件,这也会造成对国外的邮件服务器发信失败。注意:为了更有效地解决邮件发送失败问题,您应该仔细分析退信中邮件地址后的错误原因并着手解决。类似以下退信内容时,红色部分即为退信的原因:无法将您的邮件投递至以下指定地址:user@domain.com : 553 Connection block by DNSBL, [http://www.spamhaus.org/query/bl?ip=xx.xxx.x.xx]通过英文退信内容,我们可以了解到:此邮件被退是因为您的邮件服务器IP地址被反垃圾邮件组织www.spamhaus.org列入了黑名单造成的。然后您可以根据其中的地址 http://www.spamhaus.org/query/bl?ip=xx.xxx.x.xx 去该网站申请从黑名单中移除您的邮件服务器IP地址即可解决。启用以下功能可提高邮件发送成功率:1、使用DNS根服务器进行目标地址查询。方法是在服务器上点击右下角图标,然后在弹出菜单的“服务”中启用“当DNS查询MX记录失败,从DNS根服务器查询”项。2、使用中继服务器转发投递失败的邮件。方法是在服务器上点击右下角图标,然后在弹出菜单的“系统设置”–>“收发规则”中启用并正确设置“使用中继服务器转发邮件”项。

170
接口地址http协议:国内大陆优化(支持ipv4)http://ip.xsitv.com/api/openIPInfo/* API接口可能会因为各种网络原因和攻击都可能产生阻断,请开发时做好冗余和异常处理* 当HTTP请求返回的状态码非200时,请做异常处理,比如 202 状态码造成的原因可能是无效Token、余额不足、格式错误<?php
$ip = '183.44.113.246';
$datatype = 'JSON';
$token = '340a8425b71a88e5a234bada74a82rct';
$url = 'http://ip.xsitv.com/api/openIPInfo/?ip='.$ip.'&datatype='.$datatype.'&token='.$token;
$header = array('token:'.$token.'');
echo getData($url,$header);
function getData($url,$header){
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HTTPHEADER,$header);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,3);
$handles = curl_exec($ch);
curl_close($ch);
echo $handles;
}
?>查询结果JSON样式{
"code": 200,
"success": true,
"message": "查询成功",
"data": {
"ip": "183.44.113.246",
"isp": "电信",
"geo": "中国–广东–茂名"
}
}
169
“这胆子也太大了!” 近日,湖南永州一段视频在网上火了:一名男子在野外捡到一个废弃酒瓶,本以为是古董,听到里面有动静后,竟发现藏着一条冬眠的眼镜蛇。令人咋舌的是,他不仅没逃跑,反而摔碎瓶子,徒手将蛇抓起,整个过程干脆利落。据当事人周先生介绍,酒瓶是在田埂上偶然踢到的,起初以为是 “宝贝”,没细看就听到里面传来 “呼” 的一声。拿起一看,才发现是一条蛇。他推测,蛇可能是看到瓶口后钻进去过冬的,“这么小的酒瓶里藏蛇,还是头一回见。”视频中,周先生将瓶子摔碎后,七八两重的眼镜蛇从碎玻璃中露出。他眼疾手快,一把捏住蛇的七寸,直接拎了起来。按他的说法,这种蛇在当地算 “仔仔蛇”,体型不大。这段视频引发的热议背后,折射出人与野生动物相处的永恒命题。永州多丘陵湿地,自古蛇类资源丰富,当地民谚"三月三,蛇出山"至今仍在田间地头口口相传。老辈人常说,蛇冬眠时就像上了锁的匣子,但这份平静下始终藏着危险——就像周先生捏住蛇七寸时,镜头里那条眼镜蛇突然绷直的尾尖,仍在无声昭示着野性本能。事实上,类似的惊险偶遇在当地并非孤例。去年立冬前夕,隔壁村的李婶在柴垛发现过整窝越冬的银环蛇,她用火钳将它们移送到后山的举动,与周先生的做法形成有趣对照。这些代代相传的生存智慧,包含着对自然规律的深刻认知:知道蛇类立冬前后会寻找狭小空间蜷缩,明白低温下爬行动物反应迟缓,更清楚哪些树洞岩缝容易成为"蛇旅馆"。但现代社会的吊诡之处在于,当城市青年对着屏幕惊呼时,乡村年轻人正逐渐遗忘这些祖传经验。永州野生动物保护站的统计显示,近五年因误触蛇类受伤的案例中,80%是20岁以下的本地青少年。就像视频里那个被反复传阅的细节——周先生捏蛇时特意用袖口裹住虎口,这个看似随意的动作,实则是防止蛇牙勾住皮肤的古老技法。生物学家提醒,随着气候变暖,蛇类冬眠期正在缩短。或许不久的将来,我们更需要思考的不是如何徒手抓蛇,而是怎样重建对自然的敬畏之心。就像那条最终被放归山林的眼镜蛇,它游向枯草丛时划出的S形曲线,恰似给我们留下的警示符:人与野性的边界,永远需要保持安全距离。正如网友所说:“佩服的不是勇气,而是对事物的了解与稳妥处理。但危险面前,敬畏比逞强更重要。”

167
引言随着移动互联网的快速发展,移动端设备种类繁多,屏幕尺寸各异。为了提供一致的用户体验,开发者需要掌握Div+CSS技术,打造响应式移动端应用。本文将详细介绍Div+CSS在移动端响应式应用开发中的实用技巧,帮助您轻松掌握这一技能。一、Div+CSS基础1.1 Div标签Div标签是HTML文档中的一个容器,用于将文档内容进行区域划分。通过设置Div标签的样式,可以实现对页面元素的定位、布局和美化。1.2 CSS样式CSS(层叠样式表)用于描述HTML文档的外观和格式。通过编写CSS样式代码,可以控制Div标签的尺寸、颜色、边框、背景等属性。二、响应式布局响应式布局是指网页在不同设备上能够自动调整布局,以适应不同屏幕尺寸。以下是一些实现响应式布局的常用方法:2.1 流体网格布局使用百分比或视口单位(vw、vh)定义Div标签的宽度和高度,使页面元素在不同设备上自动调整大小。.container {
width: 100%;
height: 50vh;
}2.2 弹性盒模型弹性盒模型(Flexbox)是一种高效、灵活的布局方式。通过设置flex容器和flex项目的属性,可以实现对页面元素的排列、对齐和分配空间。.container {
display: flex;
justify-content: center;
align-items: center;
}
.item {
flex: 1;
}2.3 媒体查询媒体查询(Media Query)是CSS3提供的一种功能,可以根据设备的特性(如屏幕宽度、分辨率、设备方向等)应用不同的样式规则,最重要的一点 CSS文件引入的时候例如<link rel="stylesheet" type="text/css" media="screen" href="/css/index.css?v=202507140930">才生效响应效果@media screen and (max-width: 600px) {
.container {
width: 100%;
}
}三、移动端适配3.1 设备像素比设备像素比(device pixel ratio)是指设备物理像素与CSS像素的比例。在移动端开发中,需要根据设备像素比调整样式,以避免模糊或拉伸现象。3.2 视口单位视口单位(vw、vh)是相对于视口宽度和高度的百分比单位。使用视口单位可以确保元素在不同设备上保持一致的尺寸。.container {
width: 100vw;
height: 50vh;
}3.3 图片适配在移动端,需要根据设备屏幕尺寸和分辨率适配图片。可以使用CSS的background-size属性或img标签的srcset属性实现图片适配。.image {
background-size: cover;
}
img {
srcset: "image.jpg 1x, image-2x.jpg 2x";
}四、总结通过本文的学习,您应该已经掌握了Div+CSS在移动端响应式应用开发中的实用技巧。在实际开发过程中,请结合具体项目需求,灵活运用这些技巧,打造出美观、易用的移动端应用。
166
有个很头疼的事情,当市电供电,电池它是能正常充电的,太阳能逆变的时候,电池就不正常充电了,按道理来说,太阳能优先逆变给家庭设备,多余的也会一边给电池充电的,求助啊
165
一些变量说明:add_time为插入的时间to_days是sql函数,返回的是个天数data_sub(date,INTERVAL expr type)给指定的日期减去多少天data()函数返回日期或日期/时间表达式的日期部分。curdate()函数返回当前的日期 y-m-ddata_format 用于以不同的格式显示日期/时间数据period_diff(p1,p2)返回周期P1和P2之间的月数。 P1和P2格式为YYMM或YYYYMM。注意周期参数 P1 和 P2 都不是日期值1、查询今天的所有记录:(1)add_time字段,该字段为int(5)类型的select * from `article` where to_days(date_format(from_UNIXTIME(`add_time`),'%Y-%m-%d')) = to_days(now());(2)add_time字段是DATETIME类型或者TIMESTAMP类型的select * from `article` where to_days(`add_time`) = to_days(now());2、查询昨天的所有记录select * from `article` where to_days(now()) = 1 + to_days(`add_time`);3、近7天的信息记录:select * from `article` where date_sub(curdate(), INTERVAL 7 DAY) <= date(`add_time`);4、近30天的信息记录:select * from `article` where date_sub(curdate(), INTERVAL 30 DAY) <= date(`add_time`);5、查询本月的记录select * from `article` where date_format(`add_time`, ‘%Y%m') = date_format(curdate() , ‘%Y%m');6、上一个月的记录select * from `article` where period_diff(date_format(now() , ‘%Y%m') , date_format(`add_time`, ‘%Y%m')) =1;
164
php 获取 今天、昨天、这周、上周、这月、上月、近30天<?php
//今天
$today = date("Y-m-d");
//昨天
$yesterday = date("Y-m-d", strtotime(date("Y-m-d"))-86400);
//上周
$lastweek_start = date("Y-m-d H:i:s",mktime(0, 0 , 0,date("m"),date("d")-date("w")+1-7,date("Y")));
$lastweek_end = date("Y-m-d H:i:s",mktime(23,59,59,date("m"),date("d")-date("w")+7-7,date("Y")));
//本周
$thisweek_start = date("Y-m-d H:i:s",mktime(0, 0 , 0,date("m"),date("d")-date("w")+1,date("Y")));
$thisweek_end = date("Y-m-d H:i:s",mktime(23,59,59,date("m"),date("d")-date("w")+7,date("Y")));
//上月
$lastmonth_start = date("Y-m-d H:i:s",mktime(0, 0 , 0,date("m")-1,1,date("Y")));
$lastmonth_end = date("Y-m-d H:i:s",mktime(23,59,59,date("m") ,0,date("Y")));
//本月
$thismonth_start = date("Y-m-d H:i:s",mktime(0, 0 , 0,date("m"),1,date("Y")));
$thismonth_end = date("Y-m-d H:i:s",mktime(23,59,59,date("m"),date("t"),date("Y")));
//本季度未最后一月天数
$getMonthDays = date("t",mktime(0, 0 , 0,date('n')+(date('n')-1)%3,1,date("Y")));
//本季度/
$thisquarter_start = date('Y-m-d H:i:s', mktime(0, 0, 0,date('n')-(date('n')-1)%3,1,date('Y')));
$thisquarter_end = date('Y-m-d H:i:s', mktime(23,59,59,date('n')+(date('n')-1)%3,$getMonthDays,date('Y')));
?>
163
PHP 使用token验证可有效的防止非法来源数据提交访问,增加数据操作的安全性第一步:生成token/** 第一步:生成token */
public function CreateToken($userid) {
//用户名、此时的时间戳,并将过期时间拼接在一起
$time = time();
$end_time = time() + 86400;//过期时间
$info = $userid . '.' . $time . '.' . $end_time; //设置token过期时间为一天
//根据以上信息信息生成签名(密钥为 SIGNATURE 自定义全局常量)
$signature = hash_hmac('md5', $info, SIGNATURE);
//最后将这两部分拼接起来,得到最终的Token字符串
return $token = $info . '.' . $signature;
}
/** 第二步:验证token */
public function check_token($token)
{
/**** api传来的token ****/
if(!isset($token) || empty($token))
{
$msg['code']='400';
$msg['msg']='非法请求';
return json_encode($msg,JSON_UNESCAPED_UNICODE);
}
//对比token
$explode = explode('.',$token);//以.分割token为数组
if(!empty($explode[0]) && !empty($explode[1]) && !empty($explode[2]) && !empty($explode[3]) )
{
$info = $explode[0].'.'.$explode[1].'.'.$explode[2];//信息部分
$true_signature = hash_hmac('md5',$info,'siasqr');//正确的签名
if(time() > $explode[2])
{
$msg['code']='401';
$msg['msg']='Token已过期,请重新登录';
return json_encode($msg,JSON_UNESCAPED_UNICODE);
}
if ($true_signature == $explode[3])
{
$msg['code']='200';
$msg['msg']='Token合法';
return json_encode($msg,JSON_UNESCAPED_UNICODE);
}
else
{
$msg['code']='400';
$msg['msg']='Token不合法';
return json_encode($msg,JSON_UNESCAPED_UNICODE);
}
}
else
{
$msg['code']='400';
$msg['msg']='Token不合法';
return json_encode($msg,JSON_UNESCAPED_UNICODE);
}
}1、密钥设置public $secretKey = 'hgakdfkljalfdjlk';//私钥
public $termValidity = 60;//有效时常(秒)2、调用方式$info = ['user_id' => 1];
//生成密钥
$this->CreateToken( $info);
//校验密钥
$this->CheckToken($token);3、基础方法
162
引言CSS边框属性是网页设计中控制元素视觉边界的核心工具,通过设置边框的样式、宽度和颜色,可以显著提升页面的视觉层次和交互反馈。本文将系统梳理CSS边框的核心属性及其应用场景,帮助开发者全面掌握边框的使用技巧。核心边框属性详解边框样式(border-style)边框样式属性定义了边框的显示形式,支持以下值:none:无边框(默认值)solid:实线边框dashed:虚线边框dotted:点线边框double:双线边框groove:3D凹槽边框ridge:3D脊线边框inset:3D嵌入边框outset:3D突出边框<style>
.demo {
border-style: dashed solid double dotted;
/* 上右下左依次设置 */
}
</style>
<div class="demo">示例元素</div>边框宽度(border-width)边框宽度属性支持以下单位:长度值:px、em、rem等关键字:thin、medium(默认)、thick.box {
border-width: 2px 4px; /* 上下2px,左右4px */
}边框颜色(border-color)边框颜色属性支持以下格式:颜色名称:red、blue等RGB值:rgb(255, 0, 0)十六进制:#ff0000透明色:transparent.element {
border-color: red green blue yellow; /* 上右下左依次设置 */
}边框简写属性border简写属性可一次性设置所有边框的宽度、样式和颜色:.button {
border-top: 1px solid red;
border-right: 2px dashed blue;
border-bottom: 3px double green;
border-left: 4px dotted yellow;
}高级应用场景圆角边框(border-radius).circle {
width: 100px;
height: 100px;
border-radius: 50%; /* 创建圆形 */
}
.pill {
border-radius: 9999px; /* 创建胶囊形 */
}边框图像(border-image).image-border {
border: 15px solid transparent;
border-image: url('border.png') 30 round;
/* 使用图像作为边框,30px切片,round方式重复 */
}几何图形创建通过设置元素宽高为0,仅保留边框可创建三角形:.triangle {
width: 0;
height: 0;
border-left: 10px solid transparent;
border-right: 10px solid transparent;
border-bottom: 20px solid red;
}最佳实践一致性:保持同类元素的边框样式一致性能优化:避免过度使用复杂的border-image可访问性:确保边框变化提供足够的视觉反馈回退方案:为border-image提供border-style回退总结CSS边框属性是塑造元素视觉边界的基础工具,通过border-width、border-style和border-color的组合,可以实现从基础边框到复杂3D效果的多样化设计。掌握简写属性与单独边框设置的差异,结合border-radius和border-image的高级应用,能够显著提升页面的视觉表现力。在实际开发中,应注重边框样式的一致性、性能优化和可访问性,以创建既美观又实用的用户界面。
161
1,查询面页内容 b.php 面页<?php
function getiparea($ip) {
$url = 'http://ip.xsitv.com/api/openIPInfo/?ip='.$ip.'&token=340a8425b71a88e5a234bada74a82bff'; // 这是查询接口地址
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$jsonData = curl_exec($ch);
curl_close($ch);
if ($jsonData === FALSE) {
die('Error fetching data');
}
$data = json_decode($jsonData, true); // 将 JSON 字符串转换为数组
if (json_last_error() !== JSON_ERROR_NONE) {
die('Error decoding JSON');
}
// 访问多级数据结构示例
$isp = $data['data']['isp']; // 获取用户ID
$geoo = $data['data']['geo']; // 获取用户名
$geo = str_replace("–", "", $geoo);
$ip = $data['data']['ip']; // 获取用户街道地址
return $geoo.'–'.$isp;
}查询结果JSON样式
{"code":200,"success":true,"message":"操作成功","data":{"ip":"111.207.198.198","isp":"联通","geo":"中国–北京–北京"},"time":"2025-11-19 22:31:03"}2,传入要查询的IP c.php 面页<?php echo $rs["ip"]."<br>".getiparea($rs["ip"]);?>最终输入这样的效果本人是小白 有什么见解多多支教!18125039721
160
http://blog.sina.com.cn/s/blog_438308750100im0b.html我原来的公司是一家网络游戏公司,其中网站交易与游戏数据库结合通过ws实现的,但是交易记录存放在网站上,级别是千万级别的数据库是mysql数据库. 可能有人会问mysql是否支持千万级数据库,还有既然已经到了这个数据量公司肯定不差,为什么要用mysql而不用oracle这里我做一下解答 1. mysql绝对支持千万级数据库是可以肯定的, 2. 为什么选择择mysql呢? 1> 第一也是最主要的一条是mysql他能做到。 2>在第一点前提下以下的就不是太重要了,mysql相对操作简单,测试容易,配置优化也相对容易很多 3>我们这里的数据仅仅是为了记录交易保证交易是被记录的,对于查询的还是相对少只有管理后台操作中需要对数据库进行查询 4>数据结构简单,而且每条记录都非常小,因为查询速度不管和记录条数有关和数据文件大小也有直接关系. 5>我们采用的是大小表的解决办法,每天大概需要插入数据库好几百万条,这里可能还是有人怀疑,其实没问题,如果批量插入我测试的在普通的pc机子上带该一个线程并发我插入的是6千万条记录大概需要“JDBC插入6000W条数据用时:9999297ms”,小表保存最近插入的内容,把几天前的保存到大表中,这里我说的就是大表大概6-7千万条数据; 带着这些疑问和求知欲望咱们来做一个测试,因为在那个时候我也不是dba不知道人家是怎么搞的能够做成这么大的数据量,我们平时叶总探讨一些相关的内容 1.mysql的数据查询,大小字段要分开,这个还是有必要的,除非一点就是你查询的都是索引内容而不是表内容,比如只查询id等等 2.查询速度和索引有很大关系也就是索引的大小直接影响你的查询效果,但是查询条件一定要建立索引,这点上注意的是索引字段不能太多,太多索引文件就会很大那样搜索只能变慢, 3.查询指定的记录最好通过Id进行in查询来获得真实的数据.其实不是最好而是必须,也就是你应该先查询出复合的ID列表,通过in查询来获得数据 我们来做一个测试ipdatas表: CREATE TABLE `ipdatas` ( `id` INT(11) NOT NULLAUTO_INCREMENT, `uid` INT(8) NOT NULL DEFAULT'0', `ipaddress` VARCHAR(50) NOTNULL, `source` VARCHAR(255) DEFAULTNULL, `track` VARCHAR(255) DEFAULTNULL, `entrance` VARCHAR(255)DEFAULT NULL, `createdtime` DATETIME NOTNULL DEFAULT '0000-00-00 00:00:00', `createddate` DATE NOT NULLDEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `uid` (`uid`) ) ENGINE=MYISAM AUTO_INCREMENT=67086110 DEFAULTCHARSET=utf8; 这是我们做的广告联盟的推广ip数据记录表,由于我也不是mysql的DBA所以这里咱们仅仅是测试 因为原来里面有大概7015291条数据 这里我们通过jdbc的batch插入6000万条数据到此表当中“JDBC插入6000W条数据用时:9999297ms”; 大概用了两个多小时,这里面我用的是batch大小大概在1w多每次提交,还有一点是每次提交的数据都很小,而且这里用的myisam数据表,因为我需要知道mysql数据库的大小以及索引数据的大小结果是 ipdatas.MYD 3.99 GB (4,288,979,008 字节) ipdatas.MYI 1.28 GB (1,377,600,512 字节) 这里面我要说的是如果真的是大数据如果时间需要索引还是最好改成数字字段,索引的大小和查询速度都比时间字段可观。 步入正题: 1.全表搜索 返回结构是67015297条数据 SELECT COUNT(id) FROMipdatas; SELECT COUNT(uid) FROMipdatas; SELECT COUNT(*) FROMipdatas; 首先这两个全表数据查询速度很快,mysql中包含数据字典应该保留了数据库中的最大条数 查询索引条件 SELECT COUNT(*) FROM ipdatasWHERE uid=1; 返回结果时间:2分31秒594 SELECT COUNT(id) FROM ipdatasWHERE uid=1; 返回结果时间:1分29秒609 SELECT COUNT(uid) FROM ipdatasWHERE uid=1; 返回结果时间:2分41秒813 第二次查询都比较快因为mysql中是有缓存区的所以增大缓存区的大小可以解决很多查询的优化,真可谓缓存无处不在啊在程序开发中也是层层都是缓存 查询数据 第一条开始查询 SELECT * FROM ipdatas ORDER BYid DESC LIMIT 1,10 ; 31毫秒 SELECT * FROM ipdatas LIMIT1,10 ; 15ms 第10000条开始查询 SELECT * FROM ipdatas ORDER BYid ASC LIMIT 10000,10 ; 266毫秒 SELECT * FROM ipdatas LIMIT10000,10 ; 16毫秒 第500万条开始查询 SELECT * FROM ipdatas LIMIT5000000,10 ;11.312秒 SELECT * FROM ipdatas ORDER BYid ASC LIMIT 5000000,10 ; 221.985秒 这两条返回结果完全一样,也就是mysql默认机制就是id正序然而时间却大相径庭 第5000万条开始查询 SELECT * FROM ipdatas LIMIT60000000,10 ;66.563秒 (对比下面的测试) SELECT * FROM ipdatas ORDER BYid ASC LIMIT 50000000,10; 1060.000秒 SELECT * FROM ipdatas ORDER BYid DESC LIMIT 17015307,10; 434.937秒 第三条和第二条结果一样只是排序的方式不同但是用时却相差不少,看来这点还是不如很多的商业数据库,像oracle和sqlserver等都是中间不成两边还是没问题,看来mysql是开始行越向后越慢,这里看来可以不排序的就不要排序了性能差距巨大,相差了20多倍 查询数据返回ID列表 第一条开始查 select id from ipdatas orderby id asc limit 1,10; 31ms SELECT id FROM ipdatas LIMIT1,10 ; 0ms 第10000条开始 SELECT id FROM ipdatas ORDERBY id ASC LIMIT 10000,10; 68ms select id from ipdatas limit10000,10;0ms 第500万条开始查询 SELECT id FROM ipdatas LIMIT5000000,10; 1.750s SELECT id FROM ipdatas ORDERBY id ASC LIMIT 5000000,10;14.328s 第6000万条记录开始查询 SELECT id FROM ipdatas LIMIT60000000,10; 116.406s SELECT id FROM ipdatas ORDERBY id ASC LIMIT 60000000,10; 136.391s select id from ipdataslimit 10000002,10; 29.032s select id from ipdatas limit20000002,10; 24.594s select id from ipdatas limit30000002,10; 24.812s select id from ipdatas limit40000002,10; 28.750s 84.719s select id from ipdatas limit50000002,10; 30.797s 108.042s select id from ipdatas limit60000002,10; 133.012s 122.328s select * from ipdatas limit10000002,10; 27.328s select * from ipdatas limit20000002,10; 15.188s select * from ipdatas limit30000002,10; 45.218s select * from ipdatas limit40000002,10; 49.250s 50.531s select * from ipdatas limit50000002,10; 73.297s 56.781s select * from ipdatas limit60000002,10; 67.891s 75.141s select id from ipdatasorder by id asc limit 10000002,10; 29.438s select id from ipdatas orderby id asc limit 20000002,10; 24.719s select id from ipdatas orderby id asc limit 30000002,10; 25.969s select id from ipdatas orderby id asc limit 40000002,10; 29.860d select id from ipdatas orderby id asc limit 50000002,10; 32.844s select id from ipdatas orderby id asc limit 60000002,10; 34.047s 至于SELECT * ipdatas order byid asc 就不测试了 大概都在十几分钟左右 可见通过SELECT id不带排序的情况下差距不太大,加了排序差距巨大 下面看看这条语句 SELECT * FROM ipdatas WHERE idIN(10000,100000,500000,1000000,5000000,10000000,2000000,30000000,40000000,50000000,60000000,67015297); 耗时0.094ms 可见in在id上面的查询可以忽略不计毕竟是6000多万条记录,所以为什么很多lucene或solr搜索都返回id进行数据库重新获得数据就是因为这个,当然lucene/solr+mysql是一个不错的解决办法这个非常适合前端搜索技术,比如前端的分页搜索通过这个可以得到非常好的性能.还可以支持很好的分组搜索结果集,然后通过id获得数据记录的真实数据来显示效果真的不错,别说是千万级别就是上亿也没有问题,真是吐血推荐啊.上面的内容还没有进行有条件的查询仅仅是一些关于orderby和limit的测试,请关注我的下一篇文件对于条件查询的1亿数据检索测试最近做了个项目,实现对存在千万条记录的库表进行插入、查询操作。原以为对数据库的插入、查询是件很容易的事,可不知当数据达到百万甚至千万条级别的时候,这一切似乎变得相当困难。几经折腾,总算完成了任务。 1、 避免使用Hibernate框架 Hibernate用起来虽然方便,但对于海量数据的操作显得力不从心。 关于插入: 试过用Hibernate一次性进行5万条左右数据的插入,若ID使用sequence方式生成,Hibernate将分5万次从数据库取得5万个sequence,构造成相应对象后,再分五万次将数据保存到数据库。花了我十分钟时间。主要的时间不是花在插入上,而是花在5万次从数据库取sequence上,弄得我相当郁闷。虽然后来把ID生成方式改成increase解决了问题,但还是对那十分钟的等待心有余悸。 关于查询: Hibernate对数据库查询的主要思想还是面向对象的,这将使许多我们不需要查询的数据占用了大量的系统资源(包括数据库资源和本地资源)。由于对Hibernate的偏爱,本着不抛弃、不放弃的作风,做了包括配SQL,改进SQL等等的相当多的尝试,可都以失败告终,不得不忍痛割爱了。 2、 写查询语句时,要把查询的字段一一列出 查询时不要使用类似select * from x_table的语句,要尽量使用select id,name from x_table,以避免查询出不需要的数据浪费资源。对于海量数据而言,一个字段所占用的资源和查询时间是相当可观的。 3、 减少不必要的查询条件 当我们在做查询时,常常是前台提交一个查询表单到后台,后台解析这个表单,而后进行查询操作。在我们解析表单时,为了方便起见,常常喜欢将一些不需要查询的条件用永真的条件来代替(如:select count(id) from x_table where name like ‘%’),其实这样的SQL对资源的浪费是相当可怕的。我试过对于同样的近一千万条记录的查询来说,使用select count(id) from x_table 进行表查询需要11秒,而使用select count(id) from x_table where name like ‘%’却花了33秒。 4、 避免在查询时使用表连接 在做海量数据查询时,应尽量避免表连接(特别是左、右连接),万不得已要进行表连接时,被连接的另一张表数据量一定不能太大,若连接的另一张表也是数万条的话,那估计可以考虑重新设计库表了,因为那需要等待的时间决不是正常用户所能忍受的。 5、 嵌套查询时,尽可能地在第一次select就把查询范围缩到最小 在有多个select嵌套查询的时候,应尽量在最内层就把所要查询的范围缩到最小,能分页的先分页。很多时候,就是这样简单地把分页放到内层查询里,对查询效率来说能形成质的变化。 就是这些了,希望对遇到类似问题的朋友们能有所帮助!
159
dataType类型:String预期服务器返回的数据类型。如果不指定,jQuery 将自动根据 HTTP 包 MIME 信息来智能判断,比如 XML MIME 类型就被识别为 XML。在 1.4 中,JSON 就会生成一个 JavaScript 对象,而 script 则会执行这个脚本。随后 服务器端返回的数据会根据这个值解析后,传递给 回调函数。可用值: •"xml": 返回 XML 文档,可用 jQuery 处理。•"html": 返回纯文本 HTML 信息;包含的 script 标签会在插入 dom 时执行。•"script": 返回纯文本 JavaScript 代码。不会自动缓存结果。除非设置了 "cache" 参数。注意:在远程请求时(不在同一个域下),所有 POST 请求都将转为 GET 请求。(因为将使用 DOM 的 script标签来加载)•"json": 返回 JSON 数据 。•"jsonp": JSONP 格式。使用 JSONP 形式调用函数时,如 "myurl?callback=?" jQuery 将自动替换 ? 为正确的函数名,以执行 回调函数。•"text": 返回纯文本字符串
158
字体属性:(font)大小 {font-size: x-large;}(特大) xx-small;(极小) 一般中文用不到,只要用数值就可以,单位:PX、PD样式 {font-style: oblique;}(偏斜体) italic;(斜体) normal;(正常)行高 {line-height: normal;}(正常) 单位:PX、PD、EM粗细 {font-weight: bold;}(粗体) lighter;(细体) normal;(正常)变体 {font-variant: small-caps;}(小型大写字母) normal;(正常)大小写 {text-transform: capitalize;}(首字母大写) uppercase;(大写) lowercase;(小写) none;(无)修饰 {text-decoration: underline;}(下划线) overline;(上划线) line-through;(删除线) blink;(闪烁)常用字体: (font-family)"Courier New", Courier, monospace, "Times New Roman", Times, serif, Arial, Helvetica, sans-serif, Verdana背景属性: (background)色彩 {background-color: #FFFFFF;}图片 {background-image: url();}重复 {background-repeat: no-repeat;}滚动 {background-attachment: fixed;}(固定) scroll;(滚动)位置 {background-position: left;}(水平) top(垂直);简写方法 {background:#000 url(..) repeat fixed left top;} /*简写·这个在阅读代码中经常出现,要认真的研究*/区块属性: (Block) /*这个属性第一次认识,要多多研究*/字间距 {letter-spacing: normal;} 数值 /*这个属性似乎有用,多实践下*/对齐 {text-align: justify;}(两端对齐) left;(左对齐) right;(右对齐) center;(居中)缩进 {text-indent: 数值px;}垂直对齐 {vertical-align: baseline;}(基线) sub;(下标) super;(下标) top; text-top; middle; bottom; text-bottom;词间距word-spacing: normal; 数值空格white-space: pre;(保留) nowrap;(不换行)显示 {display:block;}(块) inline;(内嵌) list-item;(列表项) run-in;(追加部分) compact;(紧凑) marker;(标记) table; inline-table; table-raw-group; table-header-group; table-footer-group; table-raw; table-column-group; table-column; table-cell; table-caption;(表格标题) /*display 属性的了解很模糊*/方框属性: (Box)width:; height:; float:; clear:both; margin:; padding:; 顺序:上右下左边框属性: (Border)border-style: dotted;(点线) dashed;(虚线) solid; double;(双线) groove;(槽线) ridge;(脊状) inset;(凹陷) outset;border-width:; 边框宽度border-color:#;简写方法border:width style color; /*简写*/列表属性: (List-style)类型list-style-type: disc;(圆点) circle;(圆圈) square;(方块) decimal;(数字) lower-roman;(小罗码数字) upper-roman; lower-alpha; upper-alpha;位置list-style-position: outside;(外) inside;图像list-style-image: url(..);定位属性: (Position)Position: absolute; relative; static;visibility: inherit; visible; hidden;overflow: visible; hidden; scroll; auto;clip: rect(12px,auto,12px,auto) (裁切)css属性代码大全一 CSS文字属性:color : #999999; /*文字颜色*/font-family : 宋体,sans-serif; /*文字字体*/font-size : 9pt; /*文字大小*/font-style:itelic; /*文字斜体*/font-variant:small-caps; /*小字体*/letter-spacing : 1pt; /*字间距离*/line-height : 200%; /*设置行高*/font-weight:bold; /*文字粗体*/vertical-align:sub; /*下标字*/vertical-align:super; /*上标字*/text-decoration:line-through; /*加删除线*/text-decoration: overline; /*加顶线*/text-decoration:underline; /*加下划线*/text-decoration:none; /*删除链接下划线*/text-transform : capitalize; /*首字大写*/text-transform : uppercase; /*英文大写*/text-transform : lowercase; /*英文小写*/text-align:right; /*文字右对齐*/text-align:left; /*文字左对齐*/text-align:center; /*文字居中对齐*/text-align:justify; /*文字分散对齐*/vertical-align属性vertical-align:top; /*垂直向上对齐*/vertical-align:bottom; /*垂直向下对齐*/vertical-align:middle; /*垂直居中对齐*/vertical-align:text-top; /*文字垂直向上对齐*/vertical-align:text-bottom; /*文字垂直向下对齐*/二、CSS边框空白padding-top:10px; /*上边框留空白*/padding-right:10px; /*右边框留空白*/padding-bottom:10px; /*下边框留空白*/padding-left:10px; /*左边框留空白三、CSS符号属性:list-style-type:none; /*不编号*/list-style-type:decimal; /*阿拉伯数字*/list-style-type:lower-roman; /*小写罗马数字*/list-style-type:upper-roman; /*大写罗马数字*/list-style-type:lower-alpha; /*小写英文字母*/list-style-type:upper-alpha; /*大写英文字母*/list-style-type:disc; /*实心圆形符号*/list-style-type:circle; /*空心圆形符号*/list-style-type:square; /*实心方形符号*/list-style-image:url(/dot.gif); /*图片式符号*/list-style-position: outside; /*凸排*/list-style-position:inside; /*缩进*/四、CSS背景样式:background-color:#F5E2EC; /*背景颜色*/background:transparent; /*透视背景*/background-image : url(/image/bg.gif); /*背景图片*/background-attachment : fixed; /*浮水印固定背景*/background-repeat : repeat; /*重复排列-网页默认*/background-repeat : no-repeat; /*不重复排列*/background-repeat : repeat-x; /*在x轴重复排列*/background-repeat : repeat-y; /*在y轴重复排列*/指定背景位置background-position : 90% 90%; /*背景图片x与y轴的位置*/background-position : top; /*向上对齐*/background-position : buttom; /*向下对齐*/background-position : left; /*向左对齐*/background-position : right; /*向右对齐*/background-position : center; /*居中对齐*/五、CSS连接属性:a /*所有超链接*/a:link /*超链接文字格式*/a:visited /*浏览过的链接文字格式*/a:active /*按下链接的格式*/a:hover /*鼠标转到链接*/鼠标光标样式:链接手指 CURSOR: hand十字体 cursor:crosshair箭头朝下 cursor:s-resize十字箭头 cursor:move箭头朝右 cursor:move加一问号 cursor:help箭头朝左 cursor:w-resize箭头朝上 cursor:n-resize箭头朝右上 cursor:ne-resize箭头朝左上 cursor:nw-resize文字I型 cursor:text箭头斜右下 cursor:se-resize箭头斜左下 cursor:sw-resize漏斗 cursor:wait光标图案(IE6) p {cursor:url("光标文件名.cur"),text;}六、CSS框线一览表:border-top : 1px solid #6699cc; /*上框线*/border-bottom : 1px solid #6699cc; /*下框线*/border-left : 1px solid #6699cc; /*左框线*/border-right : 1px solid #6699cc; /*右框线*/以上是建议书写方式,但也可以使用常规的方式 如下:border-top-color : #369 /*设置上框线top颜色*/border-top-width :1px /*设置上框线top宽度*/border-top-style : solid/*设置上框线top样式*/其他框线样式solid /*实线框*/dotted /*虚线框*/double /*双线框*/groove /*立体内凸框*/ridge /*立体浮雕框*/inset /*凹框*/outset /*凸框*/七、CSS表单运用:文字方块按钮复选框选择钮多行文字方块下拉式菜单 选项1选项2八、CSS边界样式:margin-top:10px; /*上边界*/margin-right:10px; /*右边界值*/margin-bottom:10px; /*下边界值*/margin-left:10px; /*左边界值*/CSS 属性: 字体样式(Font Style)序号 中文说明 标记语法1 字体样式 {font:font-style font-variant font-weight font-size font-family}2 字体类型 {font-family:"字体1","字体2","字体3",...}3 字体大小 {font-size:数值|inherit| medium| large| larger| x-large| xx-large| small| smaller| x-small| xx-small}4 字体风格 {font-style:inherit|italic|normal|oblique}5 字体粗细 {font-weight:100-900|bold|bolder|lighter|normal;}6 字体颜色 {color:数值;}7 阴影颜色 {text-shadow:16位色值}8 字体行高 {line-height:数值|inherit|normal;}9 字 间 距 {letter-spacing:数值|inherit|normal}10 单词间距 {word-spacing:数值|inherit|normal}11 字体变形 {font-variant:inherit|normal|small-cps }12 英文转换 {text-transform:inherit|none|capitalize|uppercase|lowercase}13 字体变形 {font-size-adjust:inherit|none}14 字体 {font-stretch:condensed|expanded|extra-condensed|extra-expanded|inherit|narrower|normal| semi-condensed|semi-expanded|ultra-condensed|ultra-expanded|wider}文本样式(Text Style)序号 中文说明 标记语法1 行 间 距 {line-height:数值|inherit|normal;}2 文本修饰 {text-decoration:inherit|none|underline|overline|line-through|blink}3 段首空格 {text-indent:数值|inherit}4 水平对齐 {text-align:left|right|center|justify}5 垂直对齐 {vertical-align:inherit|top|bottom|text-top|text-bottom|baseline|middle|sub|super}6 书写方式 {writing-mode:lr-tb|tb-rl}背景样式序号 中文说明 标记语法1 背景颜色 {background-color:数值}2 背景图片 {background-image: url(URL)|none}3 背景重复 {background-repeat:inherit|no-repeat|repeat|repeat-x|repeat-y}4 背景固定 {background-attachment:fixed|scroll}5 背景定位 {background-position:数值|top|bottom|left|right|center}6 背影样式 {background:背景颜色|背景图象|背景重复|背景附件|背景位置}框架样式(Box Style)序号 中文说明 标记语法1 边界留白 {margin:margin-top margin-right margin-bottom margin-left}2 补 白 {padding:padding-top padding-right padding-bottom padding-left}3 边框宽度 {border-width:border-top-width border-right-width border-bottom-width border-left-width} 宽度值: thin|medium|thick|数值4 边框颜色 {border-color:数值 数值 数值 数值} 数值:分别代表top、right、bottom、left颜色值5 边框风格 {border-style:none|hidden|inherit|dashed|solid|double|inset|outset|ridge|groove}6 边 框 {border:border-width border-style color}上 边 框 {border-top:border-top-width border-style color}右 边 框 {border-right:border-right-width border-style color}下 边 框 {border-bottom:border-bottom-width border-style color}左 边 框 {border-left:border-left-width border-style color}7 宽 度 {width:长度|百分比| auto}8 高 度 {height:数值|auto}9 漂 浮 {float:left|right|none}10 清 除 {clear:none|left|right|both}分类列表序号 中文说明 标记语法1 控制显示 {display:none|block|inline|list-item}2 控制空白 {white-space:normal|pre|nowarp}3 符号列表 {list-style-type:disc|circle|square|decimal|lower-roman|upper-roman|lower-alpha|upper-alpha|none}4 图形列表 {list-style-image:URL}5 位置列表 {list-style-position:inside|outside}6 目录列表 {list-style:目录样式类型|目录样式位置|url}7 鼠标形状 {cursor:hand|crosshair|text|wait|move|help|e-resize|nw-resize|w-resize|s-resize|se-resize|sw-resize}
157
一、时间会告诉我们,简单的喜欢,最长远;平凡中的陪伴,最心安;懂你的人,最温暖。二、希望以后的日子里,有人给你波澜不惊的爱情,有人陪你看细水长流的风景。三、眼里没你的人,你何必放心里;情里没你的份,你何苦一往情深。但同时记住,永远不要因为新鲜感,扔掉一直陪伴你的人。四、看着不喜欢的人,学着将内心的不满沉淀,看着喜欢的人,学着将内心的情绪隐藏。五、“承诺”没有统一零售价,有时一文不值,有时千金难买。六、无论身边是否有个可以拥抱的人,真正能够温暖自己的,还是只有自己的体温。让自己变得更强大,对自己好一点,永远不会错。七、生活就是这样,总在你以为一切顺遂时,给你来个措手不及。八、我特别怕,在我主动联系某人想说什么的时候,久久得不到回应,或在多久后得到几个字的敷衍,瞬间没了说下去的心情。九、有时候你把什么放下了,不是因为突然就舍得了,而是因为期限到了,任性够了,成熟多了,也就知道这一页该翻过去了。十、愿你穿自己喜欢的衣服,和不累的人相处,和所有喜欢的一切在一起,过想象里的一百种生活。十一、最宝贵的东西不是你拥有的物质,而是陪伴在你身边的人。不能强迫别人来爱自己,只能努力让自己成为值得爱的人。十二、你应该去喜欢那些,能让你觉得自己很美好,由衷感受到温暖的人。而不是那些让你低到尘埃里,觉得自己很没用的人。十三、不怕你憨厚吃亏,也不怕你精明过人,就怕你半精办傻的,占不到便宜也交不到朋友。十四、一个人可以没有爱情,可以没有情人,但不能没有对爱情的癖好。十五、从不喜欢强迫别人做什么,你要是喜欢我就喜欢,不喜欢我也随你便。同样,你要是愿意一直陪在我身边很好,要走我也不会挽留。十六、早成者未必有成,晚达者未必不达。不可以年少而自恃,不可以年老而自弃。十七、谁也不能陪谁一辈子,谁也不是谁的谁,都只是匆匆一过客。十八、有人说,人间就是一个剧场,我们都是剧场里形形色色的演员,自己的人生总是充满着多种角色,其中最重要的一个角色就是:自己。十九、不想回的消息就不回,讨厌的人就离远一点,不开心就表现出来,不要总活在看别人脸色的生活中。二十、谎言与誓言的差别在于:一个是听的人当了真,一个是说的人用了心。二十一、我们永远不要期待别人的拯救,只有自己才能升华自己,自己准备好了多少容量,方能吸引对等的人与我们相遇,否则再美好的人出现、再动人的事情降临身边,我们也没有能量去理解与珍惜,终将擦肩而过。二十二、淡然地过着自己的生活,如果没有轰轰烈烈,那就安安心心。不是不追求,只是不去强求。二十三、时间的绝情之处在于,它让你熬到真相,却不给你任何补偿。二十四、所谓花心,就是有了感情和面包,还想吃蛋糕的情绪;所谓外遇,就是潜出围城,跌入陷阱;所谓浪漫,就是帮老婆买包心菜时,还会顺手带回一支玫瑰花;所谓厨房,就是结婚时红地毯通向的正前方……

156
ueditor上传的图片如果很大,超出编辑框,如果我们不手动调的话,保存在页面上的图片显示不全下面我就来给大家说说如果才能让UEditor插入图片尺寸自动适应编辑框大小首先我们找到如下文件:ueditor hemesiframe.css从这个文件里,就能看到有这一句:/*可以在这里添加你自己的css*/接下来,我们就可以添加调整图片尺寸的css了img {
max-width: 100%; /*图片自适应宽度*/
}
body {
overflow-y: scroll !important;
}
.view {
word-break: break-all;
}
.vote_area {
display: block;
}
.vote_iframe {
background-color: transparent;
border: 0 none;
height: 100%;
}
#edui1_imagescale{display:none !important;} /*去除点击图片后出现的拉伸边框*/
155
本文总结广东省50多年除四害的科学经验,特别是近20年蚊蝇综合治理,科学除害的科研成果和达标经验,将灭蚊蝇达标的内涵概括为:从蚊蝇生态与环境以及社会条件的整体观念出发,在调查的基础上,采取以清除,控制蚊蝇孳生地的环境治理为主的综合防治措施,运用具有中国特色的"政府组织,地方负责,部门协调,群众动手,科学治理,社会监督"的爱国卫生工作的基本方针和方法予以实施,把蚊蝇控制在国家规定的标准内.并以此展开论述灭蚊蝇达标与预防虫媒传染病发生和流行,灭蚊蝇达标对城市现代化建设与管理的促进作用,包括促进城市污水沟和河道的整治,促进厕所的改造与管理,改革垃圾收运与处理方式,促进城乡结合部一体化建设管理,规范农贸市场和建筑工地管理,促进食品加工生产企业与饮食业等特殊行业卫生设施完善与管理,灭蚊蝇达标对提高城市居民卫生和文明意识作用,提高对突发疫情,自然灾害应急消杀能力,倡导科学合理用药,保护环境等六方面对城市现代化可持续发展的作用.疫情防控灭蚊消杀记录表 整理出来供大家下载 疫情防控灭蚊消杀记录表.xls
154
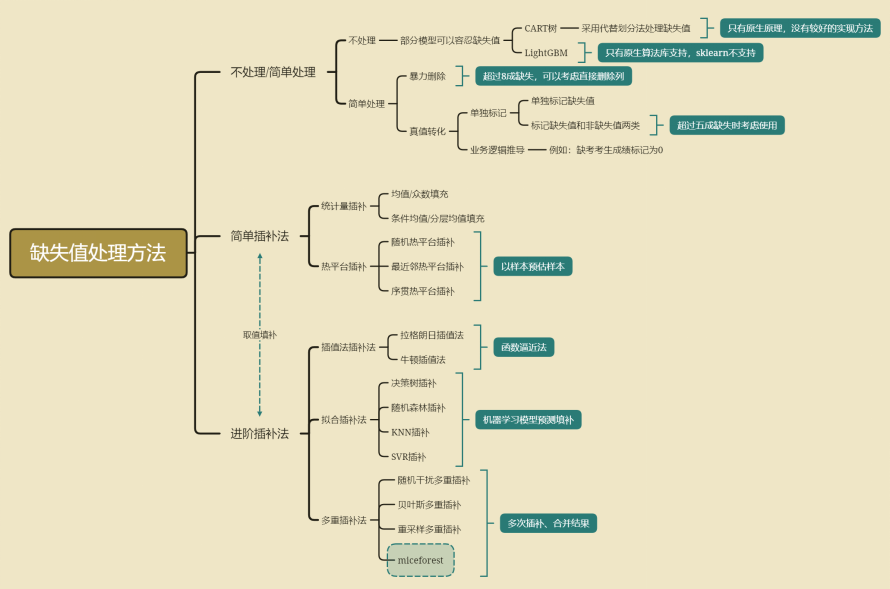
1.缺失值处理1)常见的缺失值处理方法2)实际项目开发处理方法少部分缺失,根据业务逻辑赋值,业务上认为应该填什么就填什么,业务上能解释少部分缺失,二分类问题,离散变量处理,基于业务逻辑根据Bad Rate大小,把和缺失值和非缺失值Bad Rate差不多的归为一类少部分缺失,二分类问题,连续变量处理,先使用最大KS分箱或卡方分箱或业务逻辑分箱,在把缺失值和非缺失值箱体Bad Rate差不多的归为一类。缺失值的分箱归类,主要还是看分箱是否符合业务逻辑,如果这个变量无法在合理的业务逻辑上进行分箱并获得客观的Bad Rate,最好将这个变量删除超过八成缺失,直接删除超过五成缺失,标记为缺失值和非缺失值两类,主要看变量价值(例如IV值),把null当成一种取值看待。除非对业务完全不理解,否则不建议使用众数、均值等方法直接填充def missing (df):
""" 计算每一列的缺失值及占比 """
missing_number = df.isnull().sum().sort_values(ascending=False) # 每一列的缺失值求和后降序排序
missing_percent = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False) # 每一列缺失值占比
missing_values = pd.concat([missing_number, missing_percent], axis=1, keys=['Missing_Number', 'Missing_Percent']) # 合并为一个DataFramereturn missing_values2.数据编码清洗完后的数据需要进行进一步重编码后才能带入进行建模快速验证不同模型的建模效果时,需要考虑到不同模型对数据编码要求是不同的,因此我们需要进行特征编码1)离散变量重编码不同类型的字段由不同的编码方式,例如文本类型字段可能需要用到CountVector或TF-IDF处理、时序字段可能需要分段字典排序等并且,不同模型对于数据编码类型要求也不一样,例如逻辑回归需要对多分类离散变量进行线性变换。独热编码对于二分类离散变量来说,独热编码往往是没有实际作用的。进行独热编码转化的时候会考虑只对多分类离散变量进行转化,而保留二分类离散变量#--------------------------------------独热编码 开始------------------------------------
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
def cate_colName(Transformer, category_cols, drop='if_binary'):
"""
离散字段独热编码后字段名创建函数
:param Transformer: 独热编码转化器
:param category_cols: 输入转化器的离散变量
:param drop: 独热编码转化器的drop参数
"""
cate_cols_new = []
col_value = Transformer.categories_ # 查看one-hot 列的值
for i, j in enumerate(category_cols):
if (drop == 'if_binary') & (len(col_value[i]) == 2):
cate_cols_new.append(j)
else:
for f in col_value[i]:
feature_name = j + '_' + f
cate_cols_new.append(feature_name)
return(cate_cols_new)
# 对 tcc 数据集进行多分类转化
enc = OneHotEncoder(drop='if_binary')
# 离散字段单独为一个数据集
df_cate = tcc[category_cols]
# one-hot转化
enc.fit(df_cate)
# one-hot转化后的,离散数据集
pd.DataFrame(enc.transform(df_cate).toarray(), columns=cate_colName(enc, category_cols))最后说明,非必要,不用one-hot。个人理解是,增加了特征维度,但又没有增加特征的信息量。模型的拟合能力来源于单个变量对Y的拟合能力和变量个数,每增加一个变量就增加一维,能增加模型的拟合能力,又由于独热编码产生的单个变量包含的信息量少于是乎就会造成,模型过拟合,但是预测效果又不好情况。2)连续变量分箱在实际模型训练过程中,经常需要对连续型字段进行离散化处理,也就是将连续性字段转化为离散型字段。离散之后字段的含义将发生变化,原始字段Income代表用户真实收入状况,而离散之后的含义就变成了用户收入的等级划分,0表示低收入人群、1表示中等收入人群、2代表高收入人群。连续字段的离散化能够更加简洁清晰的呈现特征信息,并且能够极大程度减少异常值的影响(例如Income取值为180的用户),同时也能够消除特征量纲影响,当然,最重要的一点是,对于很多线性模型来说,连续变量的分箱实际上相当于在线性方程中引入了非线性的因素,从而提升模型表现。当然,连续变量的分箱过程会让连续变量损失一些信息(降低了求解的精度),而对于其他很多模型来说(例如树模型),分箱损失的信息则大概率会影响最终模型效果。对于特定的数据集, 如果有充分的理由使用线性模型, 比如数据集很大或维度很高时, 但有些特征的输入和输出关系是非线性的, 那么分箱( 离散化 )是提高建模能力的好方法。使用Bad Rate方法,也能将非线性的连续变量,通过业务逻辑,按照Bad Rate大小,分箱成线性关系3)分箱说明(1)业务指标确定有明确业务背景的场景中,或许能够找到一些根据长期实践经验积累下来的业务指标来作为划分依据,例如很多金融行业会通过一些业务指标来对用户进行价值划分,例如会规定月收入10000以上属于高收入人群,此时10000就可以作为连续变量离散化的依据。(2)常见分箱方法更常见的一种情况是并没有明确的业务指标作为划分依据,此时我们就需要通过某种计算流程来进行确定。常见方法有四种,分别是等宽分箱(等距分箱)、等频分箱(等深分箱)、聚类分箱和有监督分箱等宽、等频分箱基本不用于项目开发,原因是等宽分箱会一定程度受到异常值的影响,而等频分箱又容易完全忽略异常值信息,从而一定程度上导致特征信息损失,而若要更好的兼顾变量原始数值分布,则可以考虑使用聚类分箱(3)聚类分箱先对某连续变量进行聚类(往往是KMeans聚类),然后用样本所属类别作为标记代替原始数值,从而完成分箱的过程。# 转化为列向量
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1) # 一列特征必须以列向量呈现,才能够被KBinsDiscretizer正确识别
from sklearn import cluster
kmeans = cluster.KMeans(n_clusters=3)
kmeans.fit(income) # 训练评估器
kmeans.labels_ # 通过.labels_查看每条样本所属簇的类别4)有监督分箱最大KS分箱from sklearn.metrics import roc_curve
import numpy as np
import pandas as pd
# 将类别转为类别矩阵(one-hot格式)
def class2Cmat(y):
c_name = list(np.unique(y)) # 类别名称
c_num = len(c_name) # 类别个数
cMat = np.zeros([len(y),c_num]) # 初始化类别矩阵
for i in range(c_num):
cMat[y==c_name[i],i] = 1 # 将样本对应的类别标为1
c_name = [str(i) for i in c_name] # 类别名称统一转为字符串类型
return cMat,c_name # 返回one-hot类别矩阵和类别名称
# 将切割点转换成分箱说明
def getBinDesc(bin_cut):
# 分箱说明
bin_first = ['<='+str(bin_cut[0])] # 第一个分箱
bin_last = ['>'+str(bin_cut[-1])] # 最后一个分箱
bin_desc = ['('+str(bin_cut[i])+','+str(bin_cut[i+1])+']' for i in range(len(bin_cut)-1)]
bin_desc = bin_first+bin_desc+bin_last # 分箱说明
return bin_desc
# 计算分箱详情
def statBinNum(x,y,bin_cut):
if(len(bin_cut)==0): # 如果没有切割点
return None # 返回空
bin_desc = getBinDesc(bin_cut) # 获取分箱说明
c_mat,c_name = class2Cmat(y) # 将类别转为one-hot类别矩阵
df = pd.DataFrame(c_mat,columns=c_name,dtype=int) # 将类别矩阵转为dataFrame
df['cn'] = 1 # 预设一列1,方向后面统计
df['grp'] = 0 # 初始化分组序号
df['grp_desc'] = '' # 初始化分箱说明
# 计算各个样本的分组序号与分箱说明
df.loc[x<=bin_cut[0],'grp']=0 # 第0组样本的序号
df.loc[x<=bin_cut[0],'grp_desc'] =bin_desc[0] # 第0组样本的分箱说明
for i in range(len(bin_cut)-1): # 逐区间计算分箱序号与分箱说明
df.loc[(x>bin_cut[i])&(x<=bin_cut[i+1]),'grp'] =i+1
df.loc[(x>bin_cut[i])&(x<=bin_cut[i+1]),'grp_desc'] =bin_desc[i+1]
df.loc[x>bin_cut[-1],'grp']=len(bin_cut) # 最后一组样本的序号
df.loc[x>bin_cut[-1],'grp_desc']=bin_desc[-1] # 最后一组样本的分箱说明
# 按组号聚合,统计出每组的总样本个数和各类别的样本个数
col_dict = {'grp':'max','grp_desc':'max','cn':'sum'}
col_dict.update({col:'sum' for col in c_name})
df = df.groupby('grp').agg(col_dict).reset_index(drop=True)
return df
#---------------------以上部分只用于统计分箱结果详情,与KS分箱算法无关-----------------------
# 获取ks切割点
def getKsCutPoint(x,y):
fpr, tpr, thresholds= roc_curve(y, x) # 计算fpr,tpr
ks_idx = np.argmax(abs(fpr-tpr)) # 计算最大ks所在位置
#由于roc_curve给出的切割点是>=作为右箱,而我们需要的是>作为右箱,所以切割点应向下再取一位,也即索引向上取一位
return thresholds[ks_idx+1] # 返回切割点
# 检查切割点是否有效
def checkCutValid(x,y,cutPoint,woe_asc,min_sample):
left_y = y[x<=cutPoint] # 左箱的y
right_y = y[x>cutPoint] # 右箱的y
check_sample_num = min(len(left_y),len(right_y))>=min_sample # 检查左右箱样本是否足够
left_rate = sum(left_y)/max((len(left_y)-sum(left_y)),1) # 左箱好坏比例
right_rate = sum(right_y)/max((len(right_y)-sum(right_y)),1) # 右箱好坏比例
cur_woe_asc = left_rate<right_rate # 通过好坏比例的比较,确定woe是否上升
check_woe_asc = True if woe_asc ==None else cur_woe_asc == woe_asc # 检查woe方向是否与预期一致
woe_asc = cur_woe_asc if woe_asc ==None else woe_asc # 首次woe方向为空,需要返回woe方向
cut_valid = check_sample_num & check_woe_asc # 样本足够且woe方向正确,则本次切割有效
return cut_valid,woe_asc
# 获取箱体切割点
def cutBin(bin_x,bin_y,woe_asc,min_sample):
cutPoint = getKsCutPoint(bin_x,bin_y) # 获取最大KS切割点
is_cut_valid,woe_asc = checkCutValid(bin_x,bin_y,cutPoint,woe_asc,min_sample) # 检查切割点是否有效
if( not is_cut_valid): # 如果切割点无效
cutPoint = None # 返回None
return cutPoint,woe_asc # 返回切割点
# 检查箱体是否不需再分
def checkBinFinish(y,min_sample):
check_sample_num = len(y)<min_sample # 检查样本是否足够
check_class_pure = (sum(y) == len(y))| (sum(y) == 0) # 检查样本是否全为一类
bin_finish = check_sample_num | check_class_pure # 如果样本足够或者全为一类,则不需再分
return bin_finish
# KS分箱主流程
def ksMerge(x,y,min_sample,max_bin):
# -----初始化分箱列表等变量----------------
un_cut_bins = [[min(x)-0.1,max(x)]] # 初始化待分箱列表
finish_bins = [] # 初始化已完成分箱列表
woe_asc = None # 初始化woe方向
# -----如果待分箱体不为空,则对待分箱进行分箱----------------
for i in range(10000): # 为避免有bug使用while不安全,改为for
cur_bin = un_cut_bins.pop(0) # 从待分箱列表获取一个分箱
bin_x = x[(x>cur_bin[0])&(x<=cur_bin[1])] # 当前分箱的x
bin_y = y[(x>cur_bin[0])&(x<=cur_bin[1])] # 当前分箱的y
cutPoint,woe_asc = cutBin(bin_x,bin_y,woe_asc,min_sample) # 获取分箱的最大KS切割点
if (cutPoint==None): # 如果切割点无效
finish_bins.append(cur_bin) # 将当前箱移到已完成列表
else: # 如果切割点有效
# ------检查左箱是否需要再分,需要再分就添加到待分箱列表,否则添加到已完成列表-----
left_bin = [cur_bin[0],cutPoint] # 生成左分箱
left_y = bin_y[bin_x <=cutPoint] # 获取左箱y数据
left_finish = checkBinFinish(left_y,min_sample) # 检查左箱是否不需再分
if (left_finish): # 如果左箱不需再分
finish_bins.append(left_bin) # 将左箱添加到已完成列表
else: # 否则
un_cut_bins.append(left_bin) # 将左箱移到待分箱列表
# ------检查右箱是否需要再分,需要再分就添加到待分箱列表,否则添加到已完成列表-----
right_bin = [cutPoint,cur_bin[1]] # 生成右分箱
right_y = bin_y[bin_x >cutPoint] # 获取右箱y数据
right_finish = checkBinFinish(right_y,min_sample) # 检查右箱是否不需再分
if (right_finish): # 如果右箱不需再分
finish_bins.append(right_bin) # 将右箱添加到已完成列表
else: # 否则
un_cut_bins.append(right_bin) # 将右箱移到待分箱列表
# 检查是否满足退出分箱条件:待分箱列表为空或者分箱数据足够
if((len(un_cut_bins)==0)|((len(un_cut_bins)+len(finish_bins))>=max_bin)):
break
# ------获取分箱切割点-------
bins = un_cut_bins + finish_bins # 将完成或待分的分箱一起作为最后的分箱结果
bin_cut = [cur_bin[1] for cur_bin in bins] # 获取分箱右边的值
list.sort(bin_cut) # 排序
bin_cut.pop(-1) # 去掉最后一个,就是分箱切割点
# ------------分箱说明--------------
bin_desc ='['+str(min(x))+','+str(max(x))+']' # 如果没有切割点,就只有一个分箱[min_x,max_x]
if (len(bin_cut)>0) : # 如果有切割点
bin_desc = getBinDesc(bin_cut) # 获取分箱说明
# ------------返回结果--------------
return bin_cut,bin_desc卡方分箱import numpy as np
import pandas as pd
import scipy
# 将类别转为类别矩阵(one-hot格式)
def class2Cmat(y):
c_name = list(np.unique(y)) # 类别名称
c_num = len(c_name) # 类别个数
cMat = np.zeros([len(y),c_num]) # 初始化类别矩阵
for i in range(c_num):
cMat[y==c_name[i],i] = 1 # 将样本对应的类别标为1
c_name = [str(i) for i in c_name] # 类别名称统一转为字符串类型
return cMat,c_name # 返回one-hot类别矩阵和类别名称
# 将切割点转换成分箱说明
def getBinDesc(bin_cut): # 特征数据过于集中,会导致这里分箱数不够10个
# 分箱说明
bin_first = ['<='+str(bin_cut[0])] # 第一个分箱
bin_last = ['>'+str(bin_cut[-1])] # 最后一个分箱
bin_desc = ['('+str(bin_cut[i])+','+str(bin_cut[i+1])+']' for i in range(len(bin_cut)-1)]
bin_desc = bin_first+bin_desc+bin_last # 分箱说明
return bin_desc
# 计算分箱详情
def statBinNum(x,y,bin_cut):
if(len(bin_cut)==0): # 如果没有切割点
return None # 返回空
bin_desc = getBinDesc(bin_cut) # 获取分箱说明,#特征数据过于集中,会导致这里分箱数不够10个这里就报错
c_mat,c_name = class2Cmat(y) # 将类别转为one-hot类别矩阵
df = pd.DataFrame(c_mat,columns=c_name,dtype=int) # 将类别矩阵转为dataFrame
df['cn'] = 1 # 预设一列1,方向后面统计
df['grp'] = 0 # 初始化分组序号
df['grp_desc'] = '' # 初始化分箱说明
# 计算各个样本的分组序号与分箱说明
df.loc[x<=bin_cut[0],'grp']=0 # 第0组样本的序号
df.loc[x<=bin_cut[0],'grp_desc'] =bin_desc[0] # 第0组样本的分箱说明
for i in range(len(bin_cut)-1): # 逐区间计算分箱序号与分箱说明
df.loc[(x>bin_cut[i])&(x<=bin_cut[i+1]),'grp'] =i+1
df.loc[(x>bin_cut[i])&(x<=bin_cut[i+1]),'grp_desc'] =bin_desc[i+1]
df.loc[x>bin_cut[-1],'grp']=len(bin_cut) # 最后一组样本的序号
df.loc[x>bin_cut[-1],'grp_desc']=bin_desc[-1] # 最后一组样本的分箱说明
# 按组号聚合,统计出每组的总样本个数和各类别的样本个数
col_dict = {'grp':'max','grp_desc':'max','cn':'sum'}
col_dict.update({col:'sum' for col in c_name})
df = df.groupby('grp').agg(col_dict).reset_index(drop=True)
return df
# 初始化分箱
'''
按等频分箱,等频分箱并不代表每个箱里的样本个数都一样,
因为如果每10个样本作为一个箱,刚好9-11样本的x取值一样,
那必须把9-11划到同一个箱。
'''
def initBin(x,y,bin_num=10): #特别注意,这里,等频率分箱,原始数据过于集中,会导致,分箱分不开
xx = x.copy()
xx.sort()
idx = [int(np.floor((len(x)/bin_num)*(i+1))-1) for i in range(bin_num-1)]
bin_cut = list(xx[idx])
return bin_cut
#计算卡方值
def cal_chi2(pair):
# chi2_value,p,free_n,ex = scipy.stats.chi2_contingency(pair)
pair[pair==0] = 1
class_rate = pair.sum(axis=1)/pair.sum().sum() # 两类样本的占比
col_sum = pair.sum(axis=0) # 各组别的样本个数
ex = np.dot(np.array([class_rate]).T,np.array([col_sum])) # 计算期望值
chi2 = (((pair - ex)**2/ex)).sum() # 计算卡方值
return chi2
# 计算P值
def cal_p(df):
chi2_list = [cal_chi2(np.array(df.iloc[i:i+2,:])) for i in range(df.shape[0]-1)] # 计算卡方值
grp_num = df.shape[1] # 计算组别个数
free_n = grp_num - 1 # 计算自由度
p_list = [1-scipy.stats.chi2.cdf(df=free_n, x=i) for i in chi2_list] # 计算p值
return p_list
# 卡方分箱主函数,bin_desc为分组说明
def Chi2Merge(x,y,bin_num = 5,init_bin_num=10):
# ------------初始化--------------------------------
bin_cut = initBin(x,y,bin_num=init_bin_num) # 初始化分箱
df = statBinNum(x,y,bin_cut)
df.drop(columns = ['cn'])
bin_cut.append(max(x))
df['grp_desc'] = bin_cut
c_name = list(np.unique(y))
c_name = [str(i) for i in c_name]
# ------------根据卡方值合并分箱,直到达到目标分箱数---------------------
while(df.shape[0]>bin_num):
# 计算卡方值
chi2_list = [cal_chi2(np.array(df[c_name][i:i+2])) for i in range(df.shape[0]-1)]
#将卡方值最小的两组合并
min_idx = np.argmin(chi2_list)
df.loc[min_idx+1,c_name] += df.loc[min_idx,c_name]
df.drop(min_idx, inplace = True)
df = df.reset_index(drop=True)
# ----------输出结果-----------------------------
bin_cut = list(df['grp_desc'][:-1]) # 获取切割点
bin_desc = getBinDesc(bin_cut) # 获取分箱说明
return bin_cut,bin_desc5)分箱必要性建立分类模型时,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险如在建立申请评分卡模型时用logsitic作为基模型就需要对连续变量进行离散化,离散化通常采用分箱法在银行评分卡的项目中,通常都会需要把数据分箱,分箱后并不是对数据进行WOE值替换,再放入模型离散特征的类别进行分箱二次分类(比如,中国的所有城市,通过分箱划分为县区市地区等),易于模型的快速迭代;稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;对于连续特征,分箱会降低数据的噪声影响。分箱后的数据有很强的稳定性。比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人;特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险;可以将缺失作为独立的一类带入模型。3.分组统计特征衍生策略一种同样非常常用的特征衍生方法,A特征根据B特征的不同取值进行分组统计,统计量可以是均值、方差等针对连续变量的统计指标,也可以是众数、分位数等针对离散变量的统计指标例如我们可以计算不同入网时间用户的平均月消费金额、消费金额最大值、消费金额最小值等,基本过程如下:1)注意事项A特征可以是离散变量也可以是连续变量,而B特征必须是离散变量,且最好是一些取值较多的离散变量(或者固定取值的连续变量),例如本数据集中的tenure字段,总共有73个取值。主要原因是如果B特征取值较少,则在衍生的特征矩阵中会出现大量的重复的行;计算A的分组统计量时,可以不局限于连续特征只用连续变量的统计量、离散特征只用离散的统计量,完全可以交叉使用,例如A是离散变量,我们也可以分组统计其均值、方差、偏度、峰度等,连续变量也可以统计众数、分位数等。很多时候,更多的信息组合有可能会带来更多的可能性;分组统计还可以用于多表连接的场景,例如假设现在给出的数据集不是每个用户的汇总统计结果,而是每个用户在过去的一段时间内的行为记录,则我们可以根据用户ID对其进行分组统计汇总:虑进一步围绕特征A和分组统计结果进行再一次的四则运算特征衍生,例如用月度消费金额减去分组均值,则可以比较每一位用户与相同时间入网用户的消费平均水平的差异,围绕衍生特征再次进行衍生,我们将其称为统计演变特征,也是分组汇总衍生特征的重要应用场景:2)分组统计函数封装代码def Binary_Group_Statistics(keyCol,
features,
col_num=None,
col_cat=None,
num_stat=['mean', 'var', 'max', 'min', 'skew', 'median'],
cat_stat=['mean', 'var', 'max', 'min', 'median', 'count', 'nunique'],
quant=True):
"""
双变量分组统计特征衍生函数
:param keyCol: 分组参考的关键变量
:param features: 原始数据集
:param col_num: 参与衍生的连续型变量
:param col_cat: 参与衍生的离散型变量
:param num_stat: 连续变量分组统计量
:param cat_num: 离散变量分组统计量
:param quant: 是否计算分位数
:return:交叉衍生后的新特征和新特征的名称
"""
# 当输入的特征有连续型特征时
if col_num != None:
aggs_num = {}
colNames = col_num
# 创建agg方法所需字典
for col in col_num:
aggs_num[col] = num_stat
# 创建衍生特征名称列表
cols_num = [keyCol]
for key in aggs_num.keys():
cols_num.extend([key+'_'+keyCol+'_'+stat for stat in aggs_num[key]])
# 创建衍生特征df
features_num_new = features[col_num+[keyCol]].groupby(keyCol).agg(aggs_num).reset_index()
features_num_new.columns = cols_num
# 当输入的特征有连续型也有离散型特征时
if col_cat != None:
aggs_cat = {}
colNames = col_num + col_cat
# 创建agg方法所需字典
for col in col_cat:
aggs_cat[col] = cat_stat
# 创建衍生特征名称列表
cols_cat = [keyCol]
for key in aggs_cat.keys():
cols_cat.extend([key+'_'+keyCol+'_'+stat for stat in aggs_cat[key]])
# 创建衍生特征df
features_cat_new = features[col_cat+[keyCol]].groupby(keyCol).agg(aggs_cat).reset_index()
features_cat_new.columns = cols_cat
# 合并连续变量衍生结果与离散变量衍生结果
df_temp = pd.merge(features_num_new, features_cat_new, how='left',on=keyCol)
features_new = pd.merge(features[keyCol], df_temp, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = cols_num + cols_cat
colNames_new.remove(keyCol)
colNames_new.remove(keyCol)
# 当只有连续变量时
else:
# merge连续变量衍生结果与原始数据,然后删除重复列
features_new = pd.merge(features[keyCol], features_num_new, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = cols_num
colNames_new.remove(keyCol)
# 当没有输入连续变量时
else:
# 但存在分类变量时,即只有分类变量时
if col_cat != None:
aggs_cat = {}
colNames = col_cat
for col in col_cat:
aggs_cat[col] = cat_stat
cols_cat = [keyCol]
for key in aggs_cat.keys():
cols_cat.extend([key+'_'+keyCol+'_'+stat for stat in aggs_cat[key]])
features_cat_new = features[col_cat+[keyCol]].groupby(keyCol).agg(aggs_cat).reset_index()
features_cat_new.columns = cols_cat
features_new = pd.merge(features[keyCol], features_cat_new, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = cols_cat
colNames_new.remove(keyCol)
if quant:
# 定义四分位计算函数
def q1(x):
"""
下四分位数
"""
return x.quantile(0.25)
def q2(x):
"""
上四分位数
"""
return x.quantile(0.75)
aggs = {}
for col in colNames:
aggs[col] = ['q1', 'q2']
cols = [keyCol]
for key in aggs.keys():
cols.extend([key+'_'+keyCol+'_'+stat for stat in aggs[key]])
aggs = {}
for col in colNames:
aggs[col] = [q1, q2]
features_temp = features[colNames+[keyCol]].groupby(keyCol).agg(aggs).reset_index()
features_temp.columns = cols
features_new = pd.merge(features_new, features_temp, how='left',on=keyCol)
features_new.loc[:, ~features_new.columns.duplicated()]
colNames_new = colNames_new + cols
colNames_new.remove(keyCol)
features_new.drop([keyCol], axis=1, inplace=True)
return features_new, colNames_new4.时序特征衍生使用一类仅仅通过时序特征就能够对标签进行预测的模型——时间序列模型关于时序字段的展示形式,时序字段往往记录的就是时间是真实时间,并且是精确到年-月-日、甚至是小时-分钟-秒的字段,例如"2022-07-01;14:22:01",此时拿到数据后,首先需要考虑的是如何对这类字段进行处理。一般来说时间字段的记录格式都是用'-'来划分年月日,用':'来分割时分秒,用空格、分号或者换行来分割年月日与时分秒,这是一种通用的记录方法,如果是手动输入时间,也尽可能按照上述格式进行记录除了用不同的列记录时序字段的年月日、时分秒之外,还有一些自然周期也会对结果预测有较大影响,如日期所在季度。这里需要注意的是,对于时序字段,往往我们会尽可能的对其进行自然周期的划分,然后在后续进行特征筛选时再对这些衍生字段进行筛选,对于此前的数据集,我们能够清晰的看到季度特征对标签的影响,而很多时候,除了季度,诸如全年的第几周、一周的第几天,甚至是日期是否在周末,具体事件的时间是在上午、下午还是在晚上等,都会对预测造成影响。对于这些自然周期提取方法,有些自然周期可以通过dt的方法自动计算,另外则需要手动进行计算。首先我们先看能够自动完成计算的自然周期:1)时序字段特征衍生的本质-增加分组时序字段衍生的本质:增加分组在tenure时序特征进行特征衍生后,ID1-6号用户在所属年份列中就被划分到了2019年组中,即他们同为2019年入网的用户,而根据入网的季节进行划分,则ID为0、4、5的三个用户会被划归到第一季度入网用户组中,并且时序特征衍生的字段越多、对用户分组的维度也就越多:而对用户进行分组之所以能够帮助模型进行建模与训练,其根本原因也是因为有的时候,同一组内的用户会表现出相类似的特性(或者规律),从而能够让模型更快速的对标签进行更准确的预测例如假设数据集如下所示,在原始数据集看来,标签取值毫无规律可言,但当我们对其进行时序特征的特征衍生后,立刻能发掘很多规律,例如第四季度用户都流失了、其二是2019年第一季度用户流失都流失了等等,同样,这些通过观察就能看到的规律,也很快会被模型捕捉到,而这也是时序字段衍生能够帮助模型进行更好更快的预测的直观体现:很多时候也是因为我们不知道什么样的分组能够有效的帮助到模型进行建模,因此往往需要衍生尽可能多的字段,来进行尽可能多的分组,而这些时序字段的衍生字段,也会在后续的建模过程中接受特征筛选的检验。2)时序字段衍生的核心思路-自然周期和业务周期在进行了细节时间特征的衍生之后(划分了年月日、时分秒之后),接下来的时序特征衍生就需要同时结合自然周期和业务周期两个方面进行考虑自然周期,指的是对于时间大家普遍遵照或者约定俗成的一些规定,例如工作日周末、一周七天、一年四个季度等,这也就是此前我们进行的一系列特征衍生工作,此外其实还可以根据一些业务周期来进行时序特征的划分,例如对于部分旅游景点来说,暑假是旅游旺季,并且很多是以家庭为单位进行出游(学生暑假),因此可以考虑单独将8、9月进行标记,期间记录的用户会有许多共性,而组内用户的共性就将成为后续建模效果的保障;再比如6月、11月是打折季,也可以类似的单独设一列对6月、11月进行标记等等,这些需要特征的衍生,则需要结合具体业务情况来进行判断。如果我们判断新衍生的特征在对数据分组的过程中, 不同组的数据在标签分布上并没有差别,则分组无效,我们大可不必进行如此特征衍生。例如,对于一家普通电商平台用户交易时间的秒和分,从业务角度出发,我们很难说每分钟第一秒交易的用户有哪些共同的特点,或者每小时第二分钟交易的用户有哪些共同的特点,甚至是每分钟的前30秒用户有哪些共同特点、每小时的前半个小时用户呈现出哪些共同的特点等,而这类特征就不必在衍生过程中进行创建了。但是,在另外一些场景下,例如某线下超市的周五,可能就是一个需要重点关注的时间,不仅是因为临近周末很多客户会在下班后进行集中采购、而且很多超市有“黑五”打折的习惯,如果是进行超市销售额预测,是否是周五可能就需要单独标注出来,形成独立的一列(该列被包含在dayofweek的衍生列中)。总结来看,一方面,我们需要从自然周期和业务周期两个角度进行尽可能多的特征衍生,来提供更多的备选数据分组依据来辅助模型建模,而另一方当面,我们有需要结合当前实际业务情况来判断哪些时序特征的衍生特征是有效的,提前规避掉一些可能并无太大用处的衍生特征。3)时序衍生特征函数封装代码def timeSeriesCreation(timeSeries, timeStamp=None, precision_high=False):
"""
时序字段的特征衍生
:param timeSeries:时序特征,需要是一个Series
:param timeStamp:手动输入的关键时间节点的时间戳,需要组成字典形式,字典的key、value分别是时间戳的名字与字符串
:param precision_high:是否精确到时、分、秒
:return features_new, colNames_new:返回创建的新特征矩阵和特征名称
"""
# 创建衍生特征df
features_new = pd.DataFrame()
# 提取时间字段及时间字段的名称
timeSeries = pd.to_datetime(timeSeries)
colNames = timeSeries.name
# 年月日信息提取
features_new[colNames+'_year'] = timeSeries.dt.year
features_new[colNames+'_month'] = timeSeries.dt.month
features_new[colNames+'_day'] = timeSeries.dt.day
if precision_high != False:
features_new[colNames+'_hour'] = timeSeries.dt.hour
features_new[colNames+'_minute'] = timeSeries.dt.minute
features_new[colNames+'_second'] = timeSeries.dt.second
# 自然周期提取
features_new[colNames+'_quarter'] = timeSeries.dt.quarter
features_new[colNames+'_weekofyear'] = timeSeries.dt.isocalendar().week
features_new[colNames+'_dayofweek'] = timeSeries.dt.dayofweek + 1
features_new[colNames+'_weekend'] = (features_new[colNames+'_dayofweek'] > 5).astype(int)
if precision_high != False:
features_new['hour_section'] = (features_new[colNames+'_hour'] // 6).astype(int)
# 关键时间点时间差计算
# 创建关键时间戳名称的列表和时间戳列表
timeStamp_name_l = []
timeStamp_l = []
if timeStamp != None:
timeStamp_name_l = list(timeStamp.keys())
timeStamp_l = [pd.Timestamp(x) for x in list(timeStamp.values())]
# 准备通用关键时间点时间戳
time_max = timeSeries.max()
time_min = timeSeries.min()
time_now = pd.to_datetime(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
timeStamp_name_l.extend(['time_max', 'time_min', 'time_now'])
timeStamp_l.extend([time_max, time_min, time_now])
# 时间差特征衍生
for timeStamp, timeStampName in zip(timeStamp_l, timeStamp_name_l):
time_diff = timeSeries - timeStamp
features_new['time_diff_days'+'_'+timeStampName] = time_diff.dt.days
features_new['time_diff_months'+'_'+timeStampName] = np.round(features_new['time_diff_days'+'_'+timeStampName] / 30).astype('int')
if precision_high != False:
features_new['time_diff_seconds'+'_'+timeStampName] = time_diff.dt.seconds
features_new['time_diff_h'+'_'+timeStampName] = time_diff.values.astype('timedelta64[h]').astype('int')
features_new['time_diff_s'+'_'+timeStampName] = time_diff.values.astype('timedelta64[s]').astype('int')
colNames_new = list(features_new.columns)
return features_new, colNames_new
# 测试函数使用
t = pd.DataFrame()
t['time'] = ['2022-01-03;02:31:52',
'2022-07-01;14:22:01',
'2022-08-22;08:02:31',
'2022-04-30;11:41:31',
'2022-05-02;22:01:27']
timeStamp = {'p1':'2022-03-25 23:21:52', 'p2':'2022-02-15 08:51:02'} # 关键时间戳,起始时间
features_new, colNames_new = timeSeriesCreation(timeSeries=t['time']
,timeStamp=timeStamp # 手动输入的关键时间节点的时间戳
,precision_high=True) # 是否精确到时、分、秒
# 时间精度更低一级的时序特征衍生,时分秒一般用不上
features_new, colNames_new = timeSeriesCreation(timeSeries=t['time']
,timeStamp=timeStamp # 手动输入的关键时间节点的时间戳
,precision_high=False) # 是否精确到时、分、秒
# 不添加关键时间戳
features_new, colNames_new = timeSeriesCreation(timeSeries=t['time']
,timeStamp=None # 手动输入的关键时间节点的时间戳
,precision_high=False) # 是否精确到时、分、秒
153
章鱼的“章”字来自它的吸盘:章的释义为纹章,即花纹,因章鱼每条腕足上有2~4行环形中凹的吸盘,形成繁密的圆凸纹,故得章之名。李时珍《本草纲目.鳞部》:“章鱼,形如乌贼而大,八足,身上有肉。”清李元《蠕范》卷三叫章花鱼:“身上有肉如臼,形似病痘小儿。”章鱼的吸盘蓝环章鱼而章鱼的学名“蛸”,则来自节肢动物:蛸字原指蛛形纲,蟏蛸科的肖蛸(Tetra gnatha),体细长,有八只细长的步足,八眼排成两列,在水边植株间拉网为生。因为章鱼的八只细长的腕足形似肖蛸,故把章鱼叫做“蛸”,所属下纲也成了“蛸形下纲”。清郝懿行《海错》:“八带鱼,海人名蛸,音梢。春来者名桃花蛸。头如肉弹丸,都无口目。处其口乃在腹下。多足如革带,故名八带鱼。脚下皆圆钉,有类蚕脚。其力大者钉着船不能解脱也。”所以,下次听到xx蛸的时候,可别把它默认成章鱼哦~

150
如何利用Laravel实现短信发送和接收功能,需要具体代码示例Laravel是一个流行的PHP框架,通过它可以方便地实现各种功能,包括短信的发送和接收。本文将介绍如何利用Laravel框架实现短信发送和接收功能,并提供相应的代码示例。一、短信发送功能的实现配置短信服务商要发送短信,首先需要配置短信服务商。常见的短信服务商有阿里云、腾讯云等,这里以阿里云短信为例进行说明。在.env文件中添加以下配置:ALIYUN_ACCESS_KEY_ID=your_access_key_id
ALIYUN_ACCESS_KEY_SECRET=your_access_key_secret
ALIYUN_SMS_SIGN_NAME=your_sms_sign_name
ALIYUN_SMS_TEMPLATE_CODE=your_sms_template_code将your_access_key_id和your_access_key_secret替换为你的阿里云的AccessKey ID和AccessKey Secret;将your_sms_sign_name替换为你的短信签名名称;将your_sms_template_code替换为你的短信模板代码。1.创建发送短信的方法在app/Http/Controllers目录下创建SmsController.php文件,并添加以下代码:<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
use AlibabaCloudClientAlibabaCloud;
use AlibabaCloudClientExceptionClientException;
use AlibabaCloudClientExceptionServerException;
class SmsController extends Controller
{
public function sendSms(Request $request)
{
$phoneNumber = $request->input('phone_number');
$code = $request->input('code');
AlibabaCloud::accessKeyClient(
config('app.aliyun_access_key_id'),
config('app.aliyun_access_key_secret')
)
->regionId('cn-hangzhou')
->asDefaultClient();
try {
$result = AlibabaCloud::rpc()
->product('Dysmsapi')
->host('dysmsapi.aliyuncs.com')
->version('2017-05-25')
->action('SendSms')
->method('POST')
->options([
'query' => [
'PhoneNumbers' => $phoneNumber,
'SignName' => config('app.aliyun_sms_sign_name'),
'TemplateCode' => config('app.aliyun_sms_template_code'),
'TemplateParam' => json_encode([
'code' => $code,
]),
],
])
->request();
return response()->json([
'message' => 'SMS sent successfully',
'result' => $result->toArray(),
]);
} catch (ClientException $e) {
return response()->json([
'message' => 'Client exception occurred',
'error' => $e->getErrorMessage(),
], 500);
} catch (ServerException $e) {
return response()->json([
'message' => 'Server exception occurred',
'error' => $e->getErrorMessage(),
], 500);
}
}
}3 配置路由在routes/web.php文件中添加以下代码:Route::post('/sms/send', 'SmsController@sendSms');4 发送短信可以通过发送POST请求到/sms/send路由来发送短信。请求参数中需要包含phone_number和code参数。例如,可以使用Postman工具发送以下请求:POST /sms/send HTTP/1.1
Host: your-domain.com
Content-Type: application/json
Authorization: Bearer your-token
Content-Length: 68
{
"phone_number": "your-phone-number",
"code": "123456"
}以上示例中,将your-domain.com替换为你的域名,your-token替换为你的认证令牌,your-phone-number替换为要接收短信的手机号。二、短信接收功能的实现要实现短信接收功能,可以使用第三方短信平台提供的API接口。这里以云片网为例进行讲解。1 注册云片网账号首先需要在云片网上注册账号,然后登录并获取API key。2 创建接收短信的方法在app/Http/Controllers目录下创建SmsController.php文件,并添加以下代码:<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
use IlluminateSupportFacadesHttp;
class SmsController extends Controller
{
public function receiveSms(Request $request)
{
$content = $request->input('content');
$phoneNumber = $request->input('phone_number');
// 处理短信内容的逻辑
// 返回响应
return response('success');
}
}3 配置路由在routes/web.php文件中添加以下代码:Route::post('/sms/receive', 'SmsController@receiveSms');接收短信可以通过发送POST请求到/sms/receive路由来接收短信。请求参数中需要包含content和phone_number参数。具体的短信内容处理逻辑需要根据接口文档来进行编写。例如,接收到的短信内容可以通过调用第三方API接口来进行处理。以上就是利用Laravel框架实现短信发送和接收功能的具体方法和代码示例。你可以根据自己的实际需求进行修改和扩展。希望对你有所帮助!以上就是如何利用Laravel实现短信发送和接收功能的详细内容,
149
简介:验证码短信接口在IT行业中用于验证用户身份,特别是在登录、注册等敏感操作中。PHP作为服务器端脚本语言,可以利用API接口实现短信验证码功能。本文深入探讨验证码的作用、工作原理,PHP与短信验证码接口的结合,并提供DEMO结构和接入步骤。安全注意事项和优化扩展也是本文讨论的重点。1. 验证码的重要性与作用1.1 验证码的定义与功能验证码(Completely Automated Public Turing test to tell Computers and Humans Apart),是一种区分用户是计算机还是人的公共全自动程序,广泛应用于网站登录、注册、评论等功能以防止恶意攻击和自动化操作。验证码的核心目的是为了安全,通过设置一些只有人类能轻松完成,而计算机程序难以识别的任务,来区分用户是否为真人。1.2 验证码的种类和形式验证码有着多种形态,从最初的文字型验证码到图片验证码、点击图片验证码,再到如今的短信验证码、语音验证码等。不同的验证码形式适用于不同的场景,例如短信验证码因易用性强、兼容性好,在很多场景中成为首选。1.3 验证码的作用与必要性验证码是网络安全的重要组成部分,尤其在防止自动化攻击(如暴力破解密码)、垃圾信息传播(如垃圾邮件、评论机器人)、以及保护用户账户安全等方面发挥着关键作用。随着网络攻击手段的日益复杂化,验证码技术也在不断地进化,以适应新的安全挑战。2. 短信验证码工作原理短信验证码是网络安全验证环节中不可或缺的一环,它通过短信平台向用户发送一次性密码(OTP),以便用户进行身份验证。短信验证码如何生成、传输、接收,以及如何确保整个过程的安全性和可靠性,是本章节要深入探讨的内容。2.1 短信验证码的生成机制2.1.1 验证码的算法逻辑验证码通常由一组随机数字、字母或数字字母组合构成。在生成验证码时,需要设计一套高效的算法逻辑,这个算法需要满足以下条件:- 随机性 :确保每个验证码都是独一无二的。- 复杂性 :增加自动化攻击的难度。- 易读性 :用户易于识别和输入<?php
function generateCaptchaCode($length = 6) {
$characters = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
$charactersLength = strlen($characters);
$captchaCode = '';
for ($i = 0; $i < $length; $i++) {
$captchaCode .= $characters[rand(0, $charactersLength - 1)];
}
return $captchaCode;
}
// 使用函数生成一个6位的验证码
$code = generateCaptchaCode();
echo $code; // 输出示例:3a5B9c
?>该函数 generateCaptchaCode 利用PHP的 rand() 函数从预定义的字符集中随机抽取字符,从而生成指定长度的验证码。在安全性方面,我们通常会结合当前时间戳或随机数种子,来确保每次生成的验证码都是不可预测的。2.1.2 验证码的安全特性验证码的安全性不仅来源于其随机性,还体现在以下方面:- 时效性 :验证码通常在一定时间内有效,超过时间则失效。- 验证次数限制 :对同一验证码的验证次数加以限制,防止暴力破解。- 后端校验 :客户端提交的验证码需要在服务器端进行二次校验。2.2 短信验证码的传输过程2.2.1 通道的选择与使用短信验证码通过移动运营商提供的短信通道进行传输。在选择通道时,要考虑以下因素:- 覆盖范围 :通道必须能覆盖目标用户群体的运营商。- 到达率 :通道的到达率要高,确保用户能够收到验证码。- 发送速度 :通道处理请求和发送消息的速度。为了保证短信验证码能够快速准确地发送给用户,通常会选择具有良好口碑和稳定服务的短信服务提供商。在使用过程中,开发人员需要通过API接口与短信服务商进行交互,调用相应的接口方法来发送验证码。POST /api/sendSms HTTP/1.1
Host: sms提供商的域名
Content-Type: application/json
Authorization: Bearer 你的API密钥
{
"to": "接收者的手机号",
"message": "你的验证码是:3a5B9c。请勿泄露给他人。"
}以上是通过HTTP请求发送短信的示例,实际中需要替换 to 和 message 中的内容,并且使用有效的 Authorization 头携带你的API密钥进行身份验证。2.2.2 验证码的传递效率与可靠性短信验证码的传输效率直接影响用户体验。高效率的短信发送依赖于:- 高并发处理能力 :能够快速处理大量发送请求。- 高效的错误处理机制 :在短信发送失败时能够及时重发或通知用户。在发送过程中,开发者需要监控发送状态,确保验证码能够成功到达用户手中。此外,对于发送失败的情况,应当有相应的机制进行重试或者返回错误信息给用户。验证码的工作原理是一个涉及算法、传输、安全等多个环节的复杂过程,旨在确保每一个环节都能顺畅且安全地为用户服务。通过本章节的探讨,我们对短信验证码的生成和传输机制有了全面的了解,为后续的集成和优化打下了坚实的基础。3. PHP与短信服务接口结合随着移动互联网技术的飞速发展,短信服务作为验证身份的重要手段,被广泛应用于网站与APP中。PHP作为一种广泛使用的服务器端脚本语言,如何与短信服务接口高效结合,成为了开发者必须掌握的技能之一。本章节深入探讨了PHP与短信服务提供商API的集成方式,以及核心代码的实现。3.1 集成短信服务提供商的API3.1.1 选择合适的短信服务提供商在选择短信服务提供商时,开发者需要考虑的因素包括服务的稳定性、价格、接口文档的清晰度以及用户反馈。目前市场上活跃着众多短信服务提供商,如阿里云短信服务、腾讯云短信服务、Twilio等。它们大多提供按需计费模式,使企业可以灵活地按使用量支付费用。3.1.2 API接口的申请与配置集成短信服务提供商API的第一步是访问其官网注册账号,并申请短信服务。申请成功后,通常会获得一个API Key或Access ID,以及一个Secret Key或Access Key,用于身份验证和API调用限制。这些密钥需要在开发者平台严格保密,防止泄露导致的安全风险。3.2 PHP实现短信发送的核心代码3.2.1 编写短信发送函数编写一个短信发送函数是集成短信服务的关键步骤。通常情况下,这个函数需要包括以下几个部分:API的URL、请求方法、必要的请求参数以及身份验证信息。以下是一个简单的示例代码:function sendSms($phoneNumbers, $message) {
// API Key and Secret
$accessId = 'YOUR_ACCESS_ID';
$accessKey = 'YOUR_ACCESS_KEY';
$apiUrl = 'https://api楠云短信服务.com/sms/send';
// 构建请求参数
$params = array(
'access_id' => $accessId,
'secret_key' => $accessKey,
'phone_numbers' => $phoneNumbers,
'message' => $message
);
// 将参数编码为JSON格式
$jsonParams = json_encode($params);
// 初始化cURL会话
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $apiUrl);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $jsonParams);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'Content-Type: application/json',
'Content-Length: ' . strlen($jsonParams)
));
// 执行cURL会话并获取结果
$result = curl_exec($ch);
if (curl_errno($ch)) {
echo 'Error:' . curl_error($ch);
} else {
// 对返回的JSON结果进行解码
$responseData = json_decode($result, true);
return $responseData;
}
curl_close($ch);
}3.2.2 验证码发送的代码实现在实际的验证码发送场景中,通常需要生成一个随机的验证码,并将其通过短信发送给用户。以下是实现这一功能的代码示例:function generateVerificationCode($length) {
$characters = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
$charactersLength = strlen($characters);
$verificationCode = '';
for ($i = 0; $i < $length; $i++) {
$verificationCode .= $characters[rand(0, $charactersLength - 1)];
}
return $verificationCode;
}
function sendVerificationCode($phoneNumbers) {
$codeLength = 6; // 设置验证码长度
$verificationCode = generateVerificationCode($codeLength);
$message = "您的验证码是:" . $verificationCode;
// 调用发送短信的函数
$result = sendSms($phoneNumbers, $message);
if($result['status'] == 'OK') {
// 将验证码保存到数据库中,以便后续验证
saveVerificationCodeToDatabase($phoneNumbers, $verificationCode);
return true;
} else {
return false;
}
}
// 示例:发送验证码给指定手机号
sendVerificationCode("13800138000");以上代码展示了如何生成一个6位数的随机验证码,并通过 sendSms 函数发送到指定手机号码。此外,还演示了如何将生成的验证码保存至数据库以便后续验证。本章对PHP与短信服务提供商API集成的过程进行了详细介绍,包括API的申请和配置,以及实现短信发送的函数编写。通过具体的代码示例,我们实现了验证码的生成、发送,并将验证码信息存储到数据库中以供校验使用。通过本章内容,读者应能掌握如何在PHP项目中集成短信服务,并实现基本的短信发送功能。4. PHP接口DEMO的结构组成4.1 接口DEMO的设计思路4.1.1 确定接口功能和参数开发一个PHP接口DEMO时,首先需要明确接口的功能和对外提供哪些参数。在本案例中,DEMO的目的是演示如何使用PHP与短信服务提供商API结合发送短信验证码。因此,这个接口需要完成以下几个核心任务:接收用户输入的手机号码作为请求参数;生成一个随机的六位数验证码;调用短信服务提供商的API发送验证码到指定的手机号;返回操作结果,告知用户短信发送成功或失败。为了保证接口的灵活性和易用性,我们可以通过定义接口的请求和响应参数来实现。对于请求参数,通常至少包含用户手机号( mobile ),和(可选的)操作指令( command )。对于响应参数,应包含是否发送成功( success )、错误消息( message )、以及在成功时返回的验证码( code )等信息。4.1.2 设计接口的流程图在定义好接口功能和参数之后,设计接口的流程图是至关重要的。流程图能够清晰地展示出接口的处理逻辑,帮助开发人员理解其工作方式,并且对于文档编写、测试和维护都大有帮助。下面是一个简化的流程图,展示了短信发送接口的主要步骤:graph LR
A[开始] --> B[接收手机号]
B --> C{手机号是否有效}
C -- 是 --> D[生成验证码]
C -- 否 --> E[返回错误信息]
D --> F[调用短信服务提供商API]
F --> G{发送成功?}
G -- 是 --> H[返回成功消息]
G -- 否 --> I[返回错误信息]
H --> J[结束]
I --> J
E --> J4.2 接口DEMO的代码实现4.2.1 编写接收用户请求的代码编写接口的第一步是编写接收用户请求的代码。在PHP中,通常使用全局数组 $_GET 或 $_POST 来接收用户输入的数据。以下是一个简单的PHP脚本,它定义了一个名为 sendSms 的函数,用于处理发送短信的请求:<?php
// 保存验证码,用于验证
$codeStorage = [];
function sendSms() {
// 检查请求方法和参数
if ($_SERVER['REQUEST_METHOD'] !== 'POST') {
die('请求方式不正确');
}
// 接收手机号
$mobile = isset($_POST['mobile']) ? $_POST['mobile'] : '';
// 验证手机号
if (!preg_match('/^1[3-9]d{9}$/', $mobile)) {
echo json_encode(['success' => false, 'message' => '手机号格式不正确']);
return;
}
// 生成验证码
$code = generateCode();
// 存储验证码
$_SESSION['sms_code'] = $code;
// 发送短信(这里为示例,实际中需要集成短信服务商API)
// $result = sendCodeViaSmsProvider($code, $mobile);
// 处理发送结果
if (/* 发送成功 */) {
echo json_encode(['success' => true, 'code' => $code]);
} else {
echo json_encode(['success' => false, 'message' => '短信发送失败']);
}
}
function generateCode() {
// 生成六位随机数
return rand(100000, 999999);
}
// 运行示例
sendSms();
?>在上述代码中,我们首先通过 preg_match 函数验证手机号是否符合中国大陆的手机号码规则。然后,调用 generateCode 函数生成一个六位数验证码。此验证码被存储在 $_SESSION 中用于后续验证,同时也用于模拟短信发送过程。4.2.2 集成短信服务提供商API在实际应用中,需要将 sendCodeViaSmsProvider 函数的伪代码替换为调用短信服务商实际API的代码。该API调用通常需要如下参数:API接口地址(URL);账号信息,如API Key;发送短信的目标手机号码;验证码内容;其他可能的服务提供商参数,如签名。示例代码片段可能如下所示:function sendCodeViaSmsProv
ider($code, $mobile) {
// 假设这是短信服务提供商的API地址
$apiUrl = 'https://api.smsprovider.com/send';
// API密钥和其他认证信息
$apiKey = 'your_api_key';
// 准备API请求参数
$postData = array(
'api_key' => $apiKey,
'mobile' => $mobile,
'code' => $code,
'message' => 'Your verification code is ' . $code,
// ... 其他参数 ...
);
// 使用cURL发起POST请求
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $apiUrl);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query($postData));
// 执行cURL会话
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
// 关闭cURL资源,并且释放系统资源
curl_close($ch);
// 检查HTTP响应码
if ($httpCode == 200) {
// 假定服务商返回JSON格式的数据
$responseData = json_decode($response, true);
if ($responseData['status'] == 'success') {
return true; // 发送成功
}
}
return false; // 发送失败
}// ... 上文代码 ...
try {
// 假设sendCodeViaSmsProvider调用中可能抛出异常
if (sendCodeViaSmsProvider($code, $mobile)) {
// 发送成功
echo json_encode(['success' => true, 'code' => $code]);
} else {
// 发送失败
echo json_encode(['success' => false, 'message' => '短信发送失败']);
}
} catch (Exception $e) {
// 发送过程中发生异常
echo json_encode(['success' => false, 'message' => '发送过程中出现异常: ' . $e->getMessage()]);
}
?>在以上PHP代码示例中,我们使用了try-catch结构来捕获在调用 sendCodeViaSmsProvider 函数时可能出现的异常。这样可以确保即使在遇到错误时,也能向用户提供有用的反馈信息。5. 短信验证码接入步骤5.1 系统环境的搭建5.1.1 环境需求分析在开始接入短信验证码服务之前,首先需要分析系统的基本环境需求。这包括确定操作系统、Web服务器、PHP版本以及其他依赖库的要求。例如,如果选择的是常见的LAMP(Linux、Apache、MySQL、PHP)环境,就需要安装Apache Web服务器、MySQL数据库以及PHP环境。同时,还需要确保系统的其他配置符合短信服务提供商的API接入要求。5.1.2 开发环境与生产环境的配置在完成需求分析后,接下来是配置开发环境和生产环境。开发环境中可以使用虚拟机或者Docker容器来模拟生产环境,确保开发测试的准确性。生产环境中则需要确保服务器的稳定性和安全性。通常需要考虑以下几个方面:服务器硬件配置 :包括CPU、内存、硬盘等,保证足够的性能来处理短信发送请求。网络环境 :确保服务器有稳定的公网IP和网络带宽,能够快速稳定地与短信服务提供商进行通信。安全措施 :配置防火墙规则,限制访问端口,使用SSL/TLS加密数据传输等。5.2 验证码功能的实现过程5.2.1 开发验证码接口为了实现验证码功能,需要开发一个后端接口,用于生成和发送短信验证码。以下是使用PHP语言开发的一个简单示例:<?php
// 生成随机验证码
function generateCaptchaCode($length = 6) {
$characters = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
$charactersLength = strlen($characters);
$code = '';
for ($i = 0; $i < $length; $i++) {
$code .= $characters[rand(0, $charactersLength - 1)];
}
return $code;
}
// 发送短信验证码
function sendSmsCode($phoneNumber, $code) {
// 假设已经配置了短信服务商的API信息
$apiUrl = "https://api.smsprovider.com/send";
$apiKey = "your_api_key";
$apiSecret = "your_api_secret";
// 构建发送短信的参数
$data = array(
'api_key' => $apiKey,
'phone' => $phoneNumber,
'content' => "Your verification code is: {$code}",
);
// 使用cURL发送请求
$ch = curl_init($apiUrl);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query($data));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// 执行cURL请求并获取结果
$result = curl_exec($ch);
curl_close($ch);
// 解析结果并返回是否发送成功
// ...
return true; // 假设发送成功
}
// 主逻辑
$phoneNumber = '13800138000'; // 输入的手机号码
$code = generateCaptchaCode();
if(sendSmsCode($phoneNumber, $code)) {
// 发送成功逻辑
} else {
// 发送失败逻辑
}
?>5.2.2 前端调用与用户交互在前端,通常通过JavaScript调用后端接口,将验证码发送给用户。以下是简单的前端JavaScript代码示例:// 假设后端接口为 /api/send-sms
function sendCodeToUser(phoneNumber) {
fetch('/api/send-sms', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({phone: phoneNumber}),
})
.then(response => response.json())
.then(data => {
if(data.success) {
alert('验证码已发送,请查收!');
} else {
alert('发送验证码失败,请稍后再试!');
}
})
.catch(error => {
console.error('Error:', error);
});
}
// 绑定到前端的按钮事件
document.getElementById('send-code-button').addEventListener('click', function() {
var phoneNumber = document.getElementById('phone-input').value;
sendCodeToUser(phoneNumber);
});5.3 整合到现有系统的步骤5.3.1 系统集成的难点和解决方法整合短信验证码到现有系统可能会遇到的难点包括但不限于:API兼容性问题 :不同短信服务商提供的API可能会有所不同,需要仔细阅读文档并适配现有系统。系统性能影响 :短信发送可能对系统造成额外的负载,需要通过优化或引入异步处理机制来减轻影响。用户体验 :需要确保短信发送过程对用户透明,并且在发送失败时提供适当的反馈。解决方法包括:编写适配层 :在现有系统和短信服务商API之间创建一个适配层,封装API调用细节,方便未来切换服务商或更新API。使用消息队列 :通过消息队列处理短信发送请求,将发送任务异步化,避免对主流程造成阻塞。多级用户反馈机制 :设计一套用户反馈机制,确保在短信发送成功或失败时,用户能够得到及时的反馈。5.3.2 测试与部署的注意事项在测试阶段,需要对短信验证码功能进行充分的测试,以确保其稳定性和可靠性。测试内容至少包括:功能测试 :验证短信验证码的生成、发送、验证逻辑是否正确。性能测试 :测试在高并发场景下,系统的响应时间和稳定性。安全测试 :验证系统是否有足够的安全措施,防止短信验证码被恶意利用。部署时的注意事项包括:备份现有数据 :在部署前备份现有系统数据,防止意外发生。逐步部署 :可采用灰度发布的方式,逐步将短信验证码功能上线,以便监控和处理可能出现的问题。监控和日志 :部署后,开启系统监控和日志记录功能,及时发现并处理运行中的异常。
148
一款简单实用的PHP+Ajax点击加载更多列表数据实例,实现原理:通过“更多”按钮向服务端发送Ajax请求,PHP根据分页参数查询将最新的几条记录,数据以JSON形式返回,前台Query解析JSON数据,并将数据追加到列表页。其实也是Ajax分页效果。html代码:<div id="more">
<div class="single_item">
<div class="element_head">
<div class="date"></div>
<div class="author"></div>
</div>
<div class="content"></div>
</div>
<a href="javascript:;" class="get_more">::点击加载更多内容::</a>
</div>引入jQuery插件和jquery.more.js加载更多插件:<script type="text/javascript" src="jquery.js"></script>
<script type="text/javascript" src="jquery.more.js"></script>
$(function(){
$('#more').more({'address': 'data.php'})
});data.php接收前台页面提交过来的两个参数,$_POST['last']即开始记录数,$_POST['amount']即单次显示记录数,看SQL语句就明白,其实就是分页中用到的语句。require_once('connect.php');
$last = $_POST['last'];
$amount = $_POST['amount'];
$query = mysql_query("select * from article order by id desc limit $last,$amount");
while ($row = mysql_fetch_array($query)) {
$sayList[] = array(
'title' => "<a href='http://www.xxx.com/".$row['id'].".html' target='_blank'>".$row['title']."</a>",
'author' => $row['id'],
'date' => date('m-d H:i', $row['addtime'])
);
}
echo json_encode($sayList);
146
为什么要使用div标签1.更多的配置项,那就意味着更灵活,当然,难度也更高;2.可以方便的容纳其他html标签; static定位就是不定位,出现在哪里就显示在哪里,这是默认取值,只有在你想覆盖以前的定义时才需要显示指定;relative 就是相对元素static定位时的位置进行偏移,如果指定static时top是50象素,那么指定relative并指定top是10象素时,元素实际top就是60象素了。absolute绝对定位,直接指定top,left,right,bottom。有意思 的是绝对定位也是“相对”的。它的坐标是相对其容器来说的。容器又是什么呢,容器就是离元素最近的一个定位好的“祖先”,定位好的意思就是其 Position是absolute或fixed或relative。如果没有这个容器,那就使用浏览器初始的,也就是body或者html元素。标准是 说只需要指定left和right,width可以自动根据容器宽度计算出来,可惜ie不支持。fixed:fixed才是真正的绝对定位,其位置永远相对浏览器位置来计算。而且就算用户滚动页面,元素位置也能相对浏览器保持不变,也就是说永远可以看到,这个做一些彩单的时候可以用。可惜的是ie还不支持。 可以用“流”的概念来理解div的position属性,一个html文档可以看成一棵树,relative和static是在流中的,讲究先后顺序,位置和父节点及前面的兄弟节点是相关的,而absolute和fixed不在流中,不讲先后顺序,只和父节点相关。float属性 float指定了div的浮动模式,可取none|left|right,并使div丢失clear:both和display:block的样式,并使div不会向“自动高度”的父div索要位置,在下面自动高度里有讲到。height属性 height指定里div的高度,如果指定里height属性,就算高度不够容纳所有子元素,也不会被撑开。自动高度 未指定height属性时,div就会自动计算自己的高度。使用好div的自动高度,并不是一件很容易的事,我总结了一条原则:必须高到足够容纳最后一个向自己“索要”位置的子元素。一般子元素都认为会向div索要位置,但设置了float属性的div标签是不会的代码:<div style="width:200px;border:1px solid red;">
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
</div>下面我们加点代码:<div style="width:200px;border:1px solid red;">
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="clear:both;"></div>
</div>把红色的代码上移试试:<div style="width:200px;border:1px solid red;">
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
<div style="clear:both;"></div>
<div style="float:left;width:80px;height:80px;border:1px solid blue;">TEST DIV</div>
</div>
145
在PHP中实现文章置顶功能,通常涉及到数据库的更新操作。以下是一种常见的方法,通过使用MySQL数据库和PHP脚本实现。步骤 1: 设计数据库表首先,确保你的文章表(例如名为articles)包含一个is_top字段来标识文章是否置顶。例如:CREATE TABLE articles (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
is_top TINYINT(1) DEFAULT 0
);步骤 2: 创建置顶文章的功能你可以通过一个简单的表单来允许用户选择文章并将其置顶,或者通过后台管理系统进行操作。这里我们通过后台管理系统来实现。1. 创建置顶表单(后台)在后台管理页面上,为每篇文章提供一个复选框或按钮来标记其为置顶。例如:<!-- articles.php -->
<?php
include 'config.php'; // 包含数据库配置文件
$query = "SELECT * FROM articles ORDER BY is_top DESC, created_at DESC";
$result = mysqli_query($conn, $query);
?>
<form action="set_top.php" method="post">
<table>
<tr>
<th>ID</th>
<th>Title</th>
<th>Is Top</th>
</tr>
<?php while ($row = mysqli_fetch_assoc($result)) { ?>
<tr>
<td><?php echo $row['id']; ?></td>
<td><?php echo $row['title']; ?></td>
<td><input type="checkbox" name="top_articles[]" value="<?php echo $row['id']; ?>" <?php if ($row['is_top']) echo 'checked'; ?>></td>
</tr>
<?php } ?>
</table>
<input type="submit" value="Set Top">
</form>2. 处理置顶请求(set_top.php)当用户提交表单时,这个PHP脚本将处理请求,更新数据库中的is_top字段。<?php
include 'config.php'; // 包含数据库配置文件
if (isset($_POST['top_articles'])) {
foreach ($_POST['top_articles'] as $article_id) {
$query = "UPDATE articles SET is_top = 1 WHERE id = $article_id";
mysqli_query($conn, $query);
}
} else { // 如果未选中任何文章,则取消所有文章的置顶状态(可选)
$query = "UPDATE articles SET is_top = 0";
mysqli_query($conn, $query);
}
header('Location: articles.php'); // 重定向回文章列表页面
exit;
?>步骤 3: 显示文章列表时考虑置顶状态确保在显示文章列表时,置顶的文章优先显示。你可以在查询时使用ORDER BY语句来确保置顶的文章首先显示。如上面articles.php中的SQL查询所示。注意事项:在生产环境中,确保对用户输入进行适当的验证和清理,以防止SQL注入等安全问题。可以使用预处理语句(prepared statements)来增强安全性。例如:$stmt = $conn->prepare("UPDATE articles SET is_top = ? WHERE id = ?");
$stmt->bind_param("ii", 1, $article_id); // 参数类型根据实际情况调整(这里是整型)
$stmt->execute();根据实际需求,你可能还需要在取消置顶时清除其他文章的置顶状态,或者在更新时只允许一篇文章置顶(通过设置其他文章的is_top为0)。这可以通过在更新查询中加入适当的逻辑来实现。例如,取消其他文章的置顶:$query = "UPDATE articles SET is_top = 0 WHERE id != $article_id"; // 先取消其他文章的置顶状态,然后设置当前文章的is_top为1。
mysqli_query($conn, $query); // 然后执行上面的设置is_top=1的查询。或者使用事务确保数据一致性。例如:$conn->begin_transaction(); // 开始事务处理
try {
// 先
144
在网页设计中,有时候我们需要将一个元素(如一个<div>)置于另一个元素之上或之下,以达到视觉层次的控制。这可以通过CSS的z-index属性来实现。z-index属性定义了元素的堆叠顺序,即哪个元素应该覆盖在另一个元素之上。基本使用确保包含块定位:首先,确保你的元素(特别是你想要控制的元素)具有定位属性。这通常通过设置position属性为relative、absolute或fixed来实现。使用z-index:然后,你可以通过设置z-index的值来控制这些元素的堆叠顺序。z-index的值越大,元素就越位于顶层。示例假设你有两个<div>元素,你想要一个覆盖在另一个之上<div class="background">背景</div>
<div class="foreground">前景</div>CSS.background {
position: relative; /* 或者 absolute, fixed */
z-index: 1; /* 较低的z-index */
width: 200px;
height: 100px;
background-color: blue;
}
.foreground {
position: relative; /* 或者 absolute, fixed */
z-index: 2; /* 较高的z-index */
width: 100px;
height: 50px;
background-color: red;
}
在这个例子中,.foreground(前景)会覆盖在.background(背景)之上,因为它的z-index值更高。注意事项父元素的定位:如果子元素使用了z-index,其父元素也需要有定位属性(非static),否则z-index不会生效。堆叠上下文:当多个元素具有相同的z-index值时,它们将根据在DOM中的顺序堆叠。最近的元素(在DOM树中较晚出现的)将位于顶层。默认值:如果没有设置z-index,默认值为auto,此时元素的堆叠顺序取决于其在DOM中的位置。通过合理使用z-index和定位属性,你可以精确控制网页中元素的显示顺序和层次结构



